
The National Research Council is getting ready to release a new assessment of graduate-education programs in the U.S. The previous study, published in 1995, gave each Ph.D.-granting department a numerical score between 0 and 5, then listed all the programs in each discipline in rank order. For example, here’s the top-10 list for doctoral programs in mathematics (as presented by H. J. Newton of Texas A&M University):
rank school score
1 Princeton 4.94
2 Cal Berkeley 4.94
3 MIT 4.92
4 Harvard 4.90
5 Chicago 4.69
6 Stanford 4.68
7 Yale 4.55
8 NYU 4.49
9 Michigan 4.23
10 Columbia 4.23
Note that the scores of the first two schools are identical (to two decimal places), and the first four scores differ by less than 1 percent. Given the uncertainties in the data, it seems reasonable to suppose that the ranking could have turned out differently. If the whole survey had been repeated, the first few schools might have appeared in a different order. Doctoral candidates in mathematics are presumably sophisticated enough to understand this point. Nevertheless, the spot at top of the list still carries undeniable prestige, even when you know that the distinction could be merely an artifact of statistical noise.
The committee appointed by the NRC to conduct the new graduate-school study wants to avoid this “spurious precision problem.” They’ve adopted some jazzy statistical methods—mainly a technique called resampling—to model the uncertainty in the data, and they’ve also decreed that the results will be presented differently. There will be no sorted master list showing overall ranks in descending order. Instead the programs in each discipline will be listed alphabetically, and each program will be given a range of possible ranks. For example, a program might be estimated to rank between fifth place and ninth place. Let’s call such a range of ranks a rank-interval, and denote it {5, 6, 7, 8, 9} or {5–9}.
For a hypothetical set of 10 institutions, A through J, here’s what a set of rank-intervals might look like.
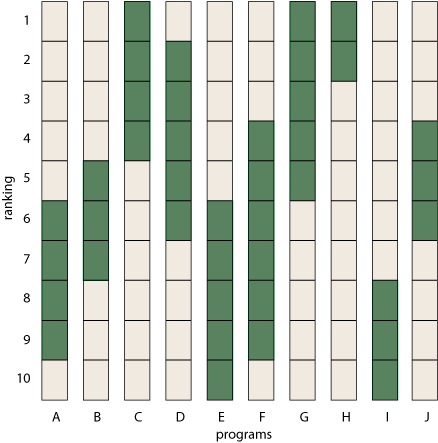
Acknowledging the uncertainty in your findings is commendable. But let’s be realistic. If you actually want to make use of these results—for example, if you’re a student choosing a grad-school program—the first thing you’re going to do is sort those bars into some sort of rank order, trying to figure out which school is best and how they all stack up against one another. In other words, you’re going to undo all the elaborate efforts the NRC committee has put into obscuring that information.
Below is one possible ordering of the bars. I have sorted first on the top of the rank-intervals, then, if two columns have the same top rank, I’ve sorted on the bottom rank. Other sorting rules give similar but not identical results. For example, sorting on the midpoints of the intervals would interchange columns B and F.
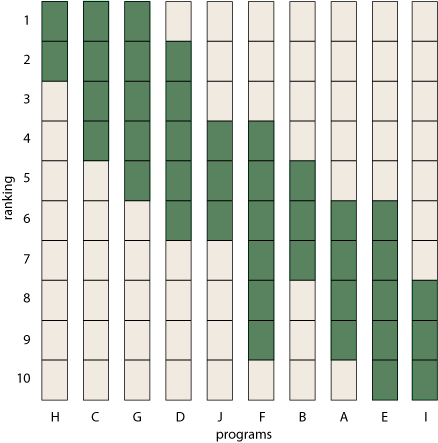
Question 1. Does sorting a set of rank-intervals by one of these simple rules yield a consistent and meaningful total ordering of the data? To put it another way, can you trust this attempt to reconstruct a ranking?
I hasten to add that this is not really a practical question about finding the best grad school. If you’re facing such a choice in real life, the NRC rank-intervals are not the only available source of information. But, for the sake of the mathematical puzzle, let’s pretend that all we know about schools A through J is embodied in those ranges of rankings.
It turns out that rank-intervals have some fairly peculiar behavior. Ranges of ratings are not a problem. If the NRC merely gave each school a fuzzy rating on the 0-to-5 scale, no one would have much trouble interpreting the results. But when you turn fuzzy ratings into fuzzy rankings, there are hidden constraints. For example, not all sets of rank-intervals are well-formed.
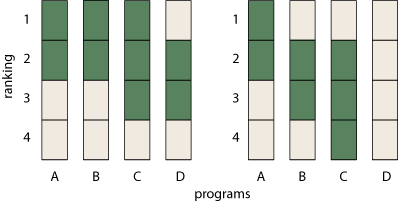
The set at left is impossible because there’s no one in last place. (We can’t all be above average.) The example at right is also nonsensical because D has no ranking at all. For a set of rank-intervals to be valid, there has to be at least one entry in each row and each column.
That’s a necessary condition, but not a sufficient one, as the two graphs below illustrate.
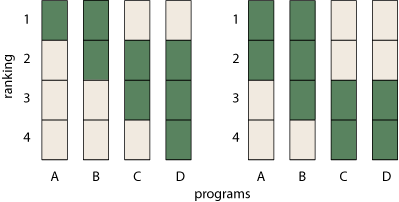
Do you see the problem with the example at left? Column B has a rank-interval of {1–2}, but in fact B can never rank first because A has no alternative to being first. The case at right is conceptually similar but a little subtler: If B is ranked third, then either first place or second place will have to remain vacant.
The underlying issue here is the presence of constraints or linkages within a set of rankings. Suppose you have calculated ratings and rankings of several schools, and then some new information turns up about one school. You can change the rating of that school without any need to adjust other ratings, but not so the ranking. If a school goes from third place to fourth place, the old fourth-place school has to move to some other rung of the ladder, and somebody has to fill the vacancy in third place. These interdependencies are obvious in a non-fuzzy ranking, but they also exist in the fuzzy case. You can’t just assign arbitrary rank-intervals to the items in a set and assume they’ll all fit together. This observation leads to a second question:
Question 2. What are the admissible sets of rank-intervals? How do we characterize them?
I have a partial answer to this question. It goes like this. Any ranking of k things must be a permutation of the integers from 1 through k. A permutation can be embodied in a permutation matrix—a square k × k matrix in which every row has a single 1, every column has a single 1, and all the other entries are 0. For example, here are the six possible 3 × 3 permutation matrices:
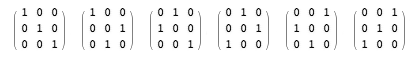
They correspond to the rankings (1, 2, 3), (1, 3, 2), (2, 1, 3), (3, 1, 2), (2, 3, 1) and (3, 2, 1).
Since a permutation matrix represents a specific (non-fuzzy) ranking, we can build up a set of rank-intervals by taking the OR-sum of two or more permutation matrices. What do I mean by an OR-sum? It’s just the element-by-element sum of the matrices using the boolean OR operator, ∨, instead of ordinary addition. OR has the following addition table:
0 ∨ 0 = 0
0 ∨ 1 = 1
1 ∨ 0 = 1
1 ∨ 1 = 1
For the first two 3 × 3 matrices shown above the arithmetic sum is:

whereas the OR-sum looks like this:
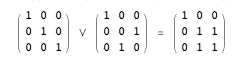
Every valid set of rank-intervals must correspond to an OR-sum of permutation matrices, simply because a set of rank-intervals is in fact a collection of permutations. The converse also holds: Any OR-sum of permutation matrices yields an admissible set of rank-intervals. Thus the OR-sums of permutation matrices—let’s call them ormats for brevity—are in one-to-one correspondence with the admissible sets of rank-intervals. (There’s just one catch when applying this idea to the NRC study. The columns of an ormat may well have “gaps,” as in the column pattern (0 1 1 0 0 1 1), which corresponds to the rank-interval {2–3, 6–7}. Will the NRC allow such discontinuous ranges in their grad-school assessments? Perhaps the issue will never come up in practice. In any case, I’m ignoring it here.)
Arithmetic sums of permutation matrices form an open-ended, infinite series; in contrast, there are only finitely many distinguishable OR-sums. The reason is easy to see: Ormats have k2 entries, each of which can take on only two possible values, and so there can’t be more than \(2^{k^{2}}\) distinct matrices. Because of the various constraints on the arrangement of the entries, the actual number of ormats is smaller. For example, at k = 3 the \(2^{k^{2}}\) upper bound allows for 512 ormats, but there are only 49:

Thus we come to the next question.
Question 3. For each k ≥ 1, how many distinct ormats can we build by OR-ing subsets of k × k permutation matrices? Is there a closed-form expression for this number?
I have answers only for puny values of k.
k upper bound # of ormats
1 1 1
2 16 3
3 512 49
4 65,536 7,443
5 33,554,432 6,092,721
6 68,719,476,736 ?
The tallies of ormats were calculated by direct enumeration, which is not a promising approach for larger k. (I note—to spare folks the bother of looking—that the sequence 1, 3, 49, 7443, 6092721 does not yet appear in the OEIS.)
To extend this series, we might try to exploit the internal structure and symmetries of the ormats. By sorting the columns and rows of the matrices, we can reduce the 49 3×3 ormats to just six equivalence classes, with the following exemplars:

Enumerating just these reduced sets of matrices should make it possible to reach larger values of k, but I have not pursued this idea. (Furthermore, the two-dimensional sorting of matrices looks to be a curiously challenging task in itself.)
By the way, I think the number of ormats will approach the \(2^{k^{2}}\) upper bound asymptotically as k increases. Many of the features that disqualify a matrix from ormathood—such as all-zero rows or columns—become rarer when k is large. I have tested this conjecture by generating random (0,1) matrices and then counting how many of them turn out to be ormats.
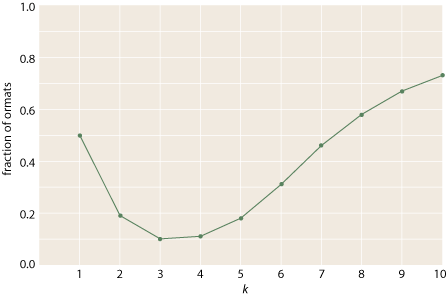
For k = 1 through 5 the results are in close agreement with the actual counts of ormats, and up to k = 10 the trend is clearly upward. But continuing this inquiry to larger values of k will depend on a positive answer to the next question.
Question 4. Given a square matrix with (0,1) entries, is there an efficient algorithm for deciding whether or not it is an OR-sum of permutation matrices, and thus an admissible set of rank-intervals?
The question asks for a recognition predicate—a procedure that will return true if a matrix is an ormat and otherwise false. If efficiency doesn’t matter, there’s no question such an algorithm exists. At worst, we can generate all the k × k ormats and see if a given matrix is among them. But that’s like saying we can factor integers by producing a complete multiplication table. It just won’t do in practice. Isn’t there a quick and easy shortcut, some distinctive property of ormats that will let us recognize them at a glance?
If we could replace the OR-sum with the ordinary arithmetic sum, the answer would be yes. Permutation matrices have the handy property that all rows and columns sum to 1. An arithmetic sum of r permutation matrices has rows and columns that all sum to r. (It is a semi-magic square.) The converse is also true (though harder to prove): If a matrix of nonnegative integers has rows and columns that all sum to r, it is a sum of r permutation matrices. This fact yields a simple test: Sum the rows and the columns and check for equality.
Unfortunately, the trick won’t work for ormats, because the boolean OR operation throws away even more information than summing does. Because 0 ∨ 1 = 1 ∨ 0 = 1 ∨ 1, infinitely many sets of operands map into the same result, and there’s no obvious way to recover the operands or even to determine how many permutation matrices entered into the OR-sum.
Maybe there’s some other clever trick for recognizing ormats, but I haven’t found it. Let me make the question more concrete. Below are three (0,1) square matrices. Two of them are ormats but the third is not. Can you tell the difference?

If it’s so hard to recognize an ormat, how did I count the ormats among a bunch of randomly generated (o,1) matrices? By hard work: I reconstructed the set of permutations allowed by each matrix. Visualize a permutation as a path threading its way through the matrix from left to right, connecting only non-zero elements and touching each column and each row just once. When you have drawn all possible permutation paths, check to see if every non-zero element is included in at least one path; if so, then the matrix is an ormat. Note that this is not an efficient recognition procedure. In the worst case (namely, an all-ones matrix), there are k! permutations, so this method has exponential running time. But k! is better than \(2^{k^2}\); and, besides, for sparse matrices the number of permutations is much smaller than k!. The 10 × 10 matrix presented as an example at the start of this post gives rise to 580 permutations, a manageable number. Here’s what they look like, plotted as a spider web of red paths across the bar chart.
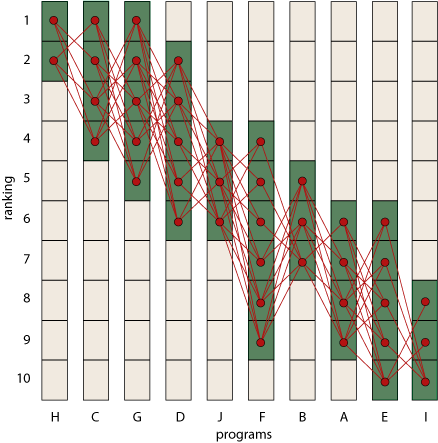
Every nonzero site is visited by at least one permutation path, so this set of rank-intervals is indeed valid.
This process of lacing permutations through a matrix finally brings me back to Question 1, about how to make sense of the NRC’s fuzzy ranking scheme. Let’s take a small example:
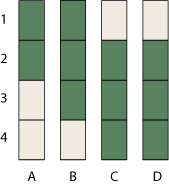
Examining the graph above shows that A must rank either first or second—but which is more likely? In the absence of more-detailed information, it seems reasonable to assume the two cases are equally likely; we assign them each a probability of 1/2. Similarly, B has the rank-interval {1–3}, and so we might suppose that each of these three cases has probability 1/3. Continuing in the same way, we assign probabilities to every element of the matrix.
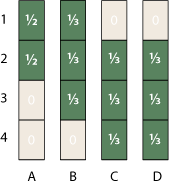
But wait! This can’t be right; our probabilities have sprung a leak. Any proper set of probabilities has to sum to 1. Our procedure assures that each column obeys this rule, but there is no such guarantee for the rows. In row 1, we’re missing one-sixth of our probability, and in row 2 we have an excess of 1/2; row 4 comes up short by 1/3.
Is there any self-consistent assignment of probabilities for the elements of this matrix? Sure. As a matter of fact, there are infinitely many such assignments, including this one:
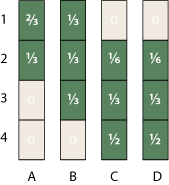
I’ll return in a moment to the question of how I plucked those particular numbers out of the air, but note first what they imply about the ranking of items A through D. For item A, with the rank-interval {1–2}, the odds are two-to-one that it ranks first rather than second. B has the behavior we expected from the outset, with probability uniformly distributed over the three cases. But if you pick either C or D, each with the rank-interval {2–4}, your chance of getting second place is only 1/6, and half the time you’ll be in last place.
Where do these numbers come from? Instead of starting with the assumption that probability is uniformly distributed over each rank-interval, assume that each possible permutation of the ranks is equiprobable. For this matrix there are six allowed permutations: (1, 2, 3, 4), (1, 2, 4, 3), (1, 3, 2, 4), (1, 3, 4, 2), (2, 1, 3, 4) and (2, 1, 4, 3). Observe that four of the six ordering put A first, and only two permutations place A second. We can also tally up such “occupation numbers” for all the other matrix elements:
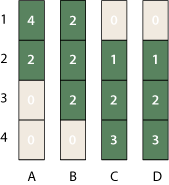
Dividing these numbers by the total number of permutations, 6, yields the probabilities given above.
We can do the same computation for the 10 × 10 example matrix, which turns out to allow 580 permutations:
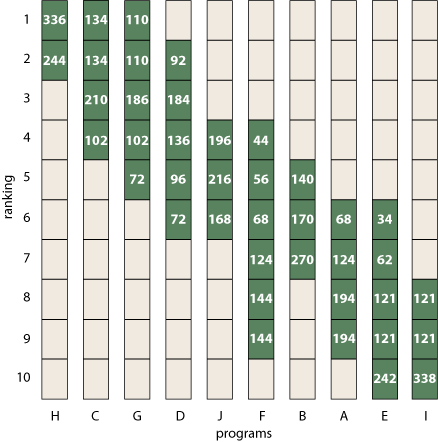
If you care to check, you’ll find that each column and each row sums to 580; dividing all the entries by this number yields a probability matrix with columns and rows that sum to 1 (also known as a doubly stochastic matrix).
This process of tabulating permutation paths recovers some of the information we would have gotten from the arithmetic sum of the permutation matrices—information that was lost in the OR-ing operation. But we get back only some of the information because we have to assume that each permutation included in the OR-sum appears only once. (This is just another way of saying that the allowed permutations are equiprobable.) There’s no particularly good reason to make this assumption, but at least it leads to a feasible probability matrix.
Is there any way of calculating the entries in the doubly stochastic matrix without explicitly tracing out all the permutation paths? I’m sure there is. I think the construction of the matrix can be approached as an integer-programming problem, and perhaps through other kinds of optimization technology. What seems less likely is that there’s some simple and efficient shortcut algorithm. But I could be wrong about that; there’s a lot of mathematics connected with this subject that I don’t understand well enough to write about (e.g., the Birkhoff polytope). I hope others will fill in the gaps.
Getting back to the assessment of grad schools—have we finally found the right way to understand those rank-intervals that the NRC promises to publish any day now? My sense is that a semi-magic square (or, equivalently, a doubly stochastic matrix) will give a less-misleading impression than a simple eyeball sorting on the spans or midpoints of the rank-intervals. But what a lot of bother to get to that point! How many prospective grad students are going to repeat this analysis?
Acknowledgment: Thanks to Geoff Davis of PhDs.org for introducing me to this story. PhDs.org will have the new ratings as soon as the NRC releases them, and may even find a way to make them intelligible! Disclaimer: I’ve done paid work for the PhDs.org web site (but this is not a paid endorsement).
Update 2010-07-27: If you’ve gotten this far, please read the comments as well. A number of commenters have provided important insights and context, which have helped me understand what’s going on in the matrices I’ve been calling ormats. But I’m still a bit murky about the best way to recognize and count them. I’m not sure that publishing my still-murky thoughts is terribly helpful, but maybe someone else will read what follows and give us a dazzling, gemlike synthesis.
For the ormat-recognition problem (Question 4 above), three basic approaches have been mentioned: enumerating the permutation paths through the matrix, examining matrix minors, and looking for perfect matchings in a bipartite graph defined by the matrix. It seems to me that all of these methods are doing the same thing.
Start with Barry Cipra’s method of minors. The basic operation is to choose a nonzero matrix element, then delete the row and the column in which that element occurs. You then apply the same operation to the remaining, smaller matrix.
In tracing permutation paths, we’re looking for sequences of nonzero elements, drawing one element from each column and each row. A way of organizing this search is to choose a nonzero element and then, after recording its location, delete the corresponding column and row, so that no other elements can be chosen from that column or row.
In the method based on Hall’s theorem, as explained by John R., we view the ormat as the adjacency matrix of a bipartite graph, where every nonzero element designates an edge connecting a row vertex to a column vertex. To find a matching, we delete an edge, along with the two vertices it connects (and also all the other edges incident on those vertices). Then we recurse on the smaller remaining graph. (See further update below.) If you translate this operation on the graph back into the language of matrices, deleting an edge and its endpoints amounts to deleting a row and a column of the adjacency matrix.
I am not asserting that these three algorithms are all identical, but they all rely on the same underlying operation. To say more, we would need to consider the control structure of the algorithms—how the basic operations are organized, how the recursion works, all the details of the bookkeeping. I don’t trust myself to make those comparisons without trying to implement the three methods, which I have not yet done. However, at this point I just don’t see how any method can guarantee correct results without something resembling backtracking (or else exhaustive search through an exponential space). After all, we’re not looking for just one matching in the graph, or one decomposition into matrix minors, or one permutation path; we have to examine them all.
Here’s a further hand-wavy argument for the essential difficulty of the task. For a (0,1) matrix, the number of permutation paths that avoid all zero entries is equal to the permanent of the matrix. Computing the permanent of such a matrix is known to be #P-complete.
Update 2010-07-31: With lots of help from my friends, I think I finally get it. Although there could be as many as k! permutation paths in a k × k matrix, you don’t need to examine all of the paths to decide whether or not the matrix is an ormat. It’s enough to establish that one such path passes through each nonzero element. This is what the algorithm based on Hall’s theorem does. As Frans points out in a comment below, I misunderstood the essential nature of that algorithm (in spite of having it explained to me several times). There is no recursive deconstruction into progressively smaller matrix minors; instead, we just loop over all the nonzero elements of the matrix, find the minor associated with each such element, then check for a perfect matching in the minor. (Still more refinements are possible—but already we have a polynomial algorithm.)
With this efficient recognizer predicate, it’s easy to measure the proportion of ormats in random matrices at larger values of k:
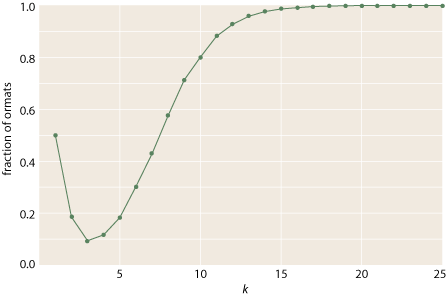
As expected, the fraction of ormats approaches 1 beyond about k = 20.
So much for identifying ormats. I am still unable to extend the series of exact counts beyond k = 5. The tabulations for random (0,1) matrices suggest that for k = 6 there should be about 20 billion ormats, and counting that high is just too painful. I need to work out the symmetries of the problem.
As far as I can tell, assigning exact probabilities to the nonzero matrix elements requires a full enumeration of all the permutation paths, and thus a calculation equivalent to the permanent. There may be a useful approximation.
Barry Cipra asks a really good question: The permanent tells us the maximum number of permutations that could possibly be included in a given ormat, but what is the minimum number? A naive upper bound is the number of 1s in the matrix, but I don’t see an easy path to an exact count. But enough for now.
The NRC will actually give five different rank-intervals for each department based on different weights of the criteria. Now go sort that!
Like the article (similar ranking silliness in the graduate CS world). Deep down what you are trying to do is find an appropriate notion of significance of the ranking which leads to fun counting problems. I once had a the honor of being a co-author on a paper exploring polynomial time algorithms (in some situations) for these sort of counting problems: “The Polytope of Win Vectors ” J. E. Bartels and J. A. Mount and D. J. A. Welsh, Annals of Combinatorics 1 1–15 (1997) http://www.mzlabs.com/JMPubs/The%20Polytope%20of%20Win%20Vectors-Bartels.pdf
This reminds me of the way I use to solve Sudoku by brute force: look at every row/column/box and perform a similar procedure to eliminate certain number-in-box possibilities. In this case, the boxes would be the rankings, and the numbers would be the programs (or the other way round, doesn’t matter because permutation matrices are closed under matrix transpose)
Hence, the applications of this work are not limited to finding reasonable fuzzy ranking systems.
Question 2 can be answered using Hall’s Theorem. Treat each rank as a variable. I.e. x_i represents the school that is ranked. Each variable has as domain the schools that could possibly have that rank. Using Hall’s Theorem one can test in linear time if all variables can be assigned. The algorithm also prunes the domains of the variables. In the case of the example in your fourth diagram it would return a smaller domain for x_1 consisting of school {A} alone.
I’m not sure exactly how their resampling works but it seems likely to give something resembling a bell curve of ranks for each school. Based on this, it seems that sorting by the midpoint of the rank interval for each school makes more sense than sorting by the upper or lower endpoints.
I came here to say exactly what Alex said (hi Alex! Unfortunately, I only post on blogs anonymously). Oh well, I was scooped, so I’ll give more detail.
Think of the matrix as the biadjacency matrix for a bipartite graph. 0 or 1 indicates the absence or presence of an edge from a row vertex to a column vertex. A ranking is a perfect matching in this graph.
As Alex said, Hall’s Marriage Theorem solves questions 2 and 4 immediately. For example, here is the efficient algorithm for question 4. The graph is “admissible” if there exists a perfect matching and if every edge is an element of some perfect matching. Therefore,
1. Test that there exists a perfect matching.
2. For each edge, test that it belongs to a perfect matching. This can be done by removing the edge and its two endpoints, and finding a matching.
I don’t know the answer to #3 (but haven’t thought about it). On the Wikipedia page, http://en.wikipedia.org/wiki/Matching_(graph_theory) , it says, “The problem of determining the number of perfect matchings in a given graph is #P Complete (see Permanent)… Also, for bipartite graphs, the problem can be approximately solved in polynomial time.[8] That is, for any ?>0, there is a probabilistic polynomial time algorithm that determines, with high probability, the number of perfect matchings M within an error of at most ?M.”
Based on the approximation algorithm mentioned, I guess it is immediate that you can efficiently determine to whatever precision you want the probabilities (one of your last questions). Apply the algorithm once for the whole graph to get the normalization factor, and then apply the algorithm again once for each edge (with that edge removed) to get the probability for that edge.
All these vague rankings seem in no way superior to the classical methods of blurring ranking information, which is to simply classify the schools as Class I, II, III, … for some reasonable number of classes. While this seems just as arbitrary, it is much easier to understand, and we do have methods for clustering numbers into groups.
What’s the precision of the probability matrix itself?
Program H has a 42% chance of being 2nd, but a 0% chance being 3rd? Even with C, G and D breathing down it’s neck?
The raw score for each school should be a distribution, but the NRC has picked some confidence level and built an interval out of it. Is it clear that that level is equal to that of the matrix? Or does all that manipulation start to compound the potential errors?
Pick any row or column of a 0-1 matrix and consider the minors corresponding to each of the non-zero entries in the chosen row or column (i.e., the (k-1)x(k-1) matrix obtained by eliminating the row and column of the non-zero entry). It’s easy to see that the large matrix is an ormat if and only if each and every one of the minors is an ormat. This suggests a recursive algorithm with a greedy aspect: Pick a row or column with a minimal number of 1′s and recursively invoke the same process for each of the minors.
This clearly bogs down for large values of k, and may even occasionally get hung up in moderate-sized cases, but it should be sufficiently efficient to extend the computations for the graph prompting Question 4, maybe out to around k=20. After all, a random 0-1 matrix is likely to have at least one row or column with a “smaller than average” number of 1′s. At the very least, greedy recursion fairly quickly spots which of the three 5×5 matrices you asked about is not an ormat (and confirms that the other two are).
Oh dear, let me withdraw that last comment. What I said is easy to see is only easy to see if you’re not thinking very carefully. It’s just not true!
OK, I’ve thought things over somewhat more carefully, and I’m prepared to partially withdraw my withdrawal. The greedy recursion I initially proposed can be made to work — and then vastly improved — with a minor modification.
The fly in the ointment occurs when your minimal row or column has a single 1 in it. If that entry is also the only 1 in its column or row, everything is OK, you just recurse on its minor. But if there’s another 1, you should instead stop then and there and declare the whole shebang as not an ormat. So I really should have said the following is easy to see:
Pick any row or column of the matrix in question. By transposing things if necessary, we can say we’ve picked a row. If the row has more than one 1, the matrix is an ormat if and only if each of the minors corresponding to the row’s 1′s is an ormat. If the row has a single 1, then the matrix is an ormat if and only if that entry is the only 1 in its column and its minor is an ormat. (And if the row has no 1′s at all, the matrix is obviously not an ormat.)
It may be a good idea at this point to see why that’s easy to see.
Since ormats are defined as OR-sums of permutation matrices, it’s clear we’re free to permute rows and columns at will, as well as transposing, so without loss of generality, we can assume we’ve picked the first row, whose nonzero entries are in its first few columns. If there’s a single 1 in the first row, but more than that one 1 in the first column, then clearly the matrix is not an ormat: those other 1′s cannot be accounted for as coming from any permutation matrix, because any such matrix would have to have a nonzero entry elsewhere in the first row. In essence, row one having its only nonzero entry in column one says that First Place can only go to Institution One, hence it makes no sense to ever talk about it coming in second or lower.
On the other hand, if the 1 in the (1,1) position is the only 1 in both its row and column, then it’s equally clear we need only check that its minor is an ormat. That is, each of the minor’s 1′s is accounted for by a permutation that rates Institutions 2-k in Positions 2-k.
Of course it goes almost without saying that if the first row has no 1′s, the matrix can’t possibly be an ormat.
Finally, if there are multiple 1′s in the first row, then we need to check that each of them is accounted for by some permutation matrix. This is certainly true if each of their minors is an ormat. But what’s most important here is that, by checking that each minor is an ormat, you’ve now verified (in some cases, multiple times!) that each of the 1′s below the first row is accounted for as coming from some permutation matrix. This doesn’t happen for all 1′s if there’s only a single 1 in the first row, but it does as soon as there is a second 1.
So it’s clear by now, I hope, that greedy recursion, suitably modified, does the trick. But in fact it’s possible to do even better. Here’s how.
Pick any nonzero entry and, by permuting rows and columns, move it to the (1,1) position. If it’s the only 1 in the first row, check if it’s the only the only 1 in the first column. If it isn’t, you can declare the matrix as non-ormat; if it is, apply this algorithm (recursively) to its minor. If there’s a second 1 in the first row and in the first column, apply the algorithm to all three minors. Without loss of generality (by permuting rows and/or columns as necessary), we can assume these other 1′s are the (1,2) and (2,1) entries. The large matrix is an ormat if and only if all three minors are ormats.
That’s because the (1,1) minor being ormat establishes that the (1,1) entry and all the 1′s below it and to its right are accounted for by some permutation, so it remains to verify that the other 1′s in the first row and in the first column are accounted for. Checking that the (1,2) minor is ormat establishes that the rest of the 1′s in the first column are accounted for, and checking that the (2,1) minor is ormat does the same for the rest of the 1′s in the first row. (The converse is also obvious: if the minor of some 1 is not ormat, that 1 cannot come from any permuation matrix.)
This still bogs down for large k, but its complexity is only order 3^k-ish instead of k!-ish, so it looks even more likely to be useful out to around k=20. I’m sorry to be so rambling, but I thought it best not to try to be too terse this time.
Rats! My apologies to anyone who spent time trying to read the previous posting, withdrawing the withdrawal. It’s all nonsense.
It *is* true (I think) that if every minor looked at by the algorithm(s) I outlined turns out to be an ormat, then your matrix is an ormat, and what I said about the ormaticity of (sub)matrices with a row or column having a single 1 is also correct (I think). But the “only if” part of the algorithm is most certainly false, as the very simplest example shows:
1 1 1
1 1 1
1 1 0
The (1,1) minor here is
1 1
1 0
which is NOT an ormat, but the 3×3 matrix IS an ormat.
Sorry!
Brian, just an afterthought: It might be helpful to your audience if you inserted an editorial comment at the top of my 8:15 post warning people not to bother reading it carefully, but to look at the subsequent retraction instead.
Barry, Alex already posted a polynomial-time algorithm…
James, I wouldn’t say the approach I described is worthless because it’s based on an exponential-time algorithm. It’s worthless because it’s WRONG. To the question, Is this (large) matrix omat?, it tends to say No even when the correct answer is Yes. (It has the minor virtue of never saying Yes when the answer should be No, but that’s not much of a virtue, especially if it simply always, or almost always, says No.)
I was beguiled by the notion that one might approach Brian’s Question 4 with a conceptually simple recursive algorithm, in essence answering the question, Is this (large) matrix ormat? by asking the same question of a relatively small set of slightly smaller matrices. It was clear from the get-go that such an approach would be exponential-time, but it occurred to me that its simplicity would nonetheless leave it practical enough to extend Brian’s calculations for a few more values of k, past what he’d been able to do by sheer brute force. I do think what I described could well be run in a reasonable amount of time for most random 0-1 matrices up to around k=20. The problem is, the results would be worthless.
It’s not entirely clear to me that the algorithm Alex (and John R.) posted, invoking Hall’s Marriage Theorem, is necessarily practical — or even obviously polynomial-time. When I looked up Hall’s theorem on Wikipedia, the application to bipartite graphs (with edges connecting vertices in a set S with those in a set T of equal size) simply says there is a perfect matching if and only if a certain inequality holds FOR ALL SUBSETS of S. So unless there’s more to the theorem, or some additional cleverness, you’re looking at a 2^k-ish computation. What am I not seeing here that makes Hall’s theorem into a linear-time test, as Alex says it is?
It is polynomial time, not linear time. In the cited Wikipedia link, or here http://en.wikipedia.org/wiki/Hopcroft-Karp_algorithm , it says that a maximum matching can be found in O(k^{5/2}) time, where k is the number of vertices/dimension of the matrix. There are several other efficient algorithms; this is a very well-studied problem.
What am I not seeing here that makes Hall’s theorem into a linear-time test, as Alex says it is?
Its linear time when the ranges are [1..n] and contiguous as they are in this case.
If the ranges are not contiguous, e.g. a university is either 2nd or 7th or 9-11th, then the best running time is achieved with a general matching algorithm with best known complexity of O(n^2.5) as James said.
Not to beat a dead horse completely into the ground, but I think it’s worth clarifying the similarities and differences between my failed approach to deciding whether a given k x k 0-1 matrix is ormat and the polynomial-time approach based on Hall’s Marriage Theorem for perfect matchings. (Many thanks to James for pinpointing the O(k^2.5)-time Hopcroft-Karp algorithm. It’s good to know I wasn’t not seeing something utterly obvious and trivial!)
The most telling and important difference, of course, is that my approach produces an algorithm that gives wrong answers, whereas the perfect-matching approach actually solves the problem correctly. But let’s such minor matters aside, and just consider what the two approaches do to get the answers they do.
The two approaches are similar in that they each answer the question, Is this 0-1 matrix an ormat?, by asking a related question about a batch of minors corresponding to some or all of the nonzero entries and, in effect, AND-ing the answers together. But that’s where the similarity ends.
Modulo a few details that are at this point irrelevant, my approach essentially asks the exact same question — Is this 0-1 matrix an ormat? — about exactly three minors. The perfect-matching approach, on the other hand, asks a *different* question — Does this 0-1 matrix contain a permutation matrix? — about *all* the minors (corresponding to nonzero entries). In both approaches, the answer has to be Yes for each minor query in order for the overall answer to be Yes — as soon as you get a No, you can stop.
By asking the exact same question at each level, my approach is naturally recursive, and one can imagine implementing it as a fairly simple (albeit inefficient) program. It’s truly a shame it gives wrong answers! (As I said in an early posting, if it does return the overall answer Yes, you know you’ve got the correct answer. Unfortunately, it appears likely that it almost always stumbles across an incorrect No.)
The perfect-matching approach uses the Hopcroft-Karp algorithm (or some equivalent) to answer the questions about the minors. So it’s more of a subroutine, or function call, approach than recursive. The Hopcroft-Karp portion looks subtle enough to be a mild programming challenge. (The Wikipedia description boils it down to four key steps, but I’ll be the first to admit I don’t understand all the verbiage.)
It’s worth noting that although the Hopcroft-Karp algorithm runs in O(k^2.5) time, it has to be run for each minor corresponding to a nonzero entry in the k x k matrix, of which there are O(k^2), so a straightforward subroutine implementation results in a O(k^4.5)-time algorithm. That’s probably still practical for small to moderate values of k, but it’s good to keep in mind that at some power of k, even theoretically efficient, polynomial-time algorithms get a little dicey, so there’s still a roll for the occasional exponential-time horse and buggy. That said, however, it’s certainly the case that a polynomial-time algorithm that gives correct answers is infinitely preferable to an exponential-time algorithm that’s almost always wrong!
“The Hopcroft-Karp portion looks subtle enough to be a mild programming challenge.”
Graph algorithms like this are everywhere on the internet, take it from a toolbox. But as Alex says, with contiguous intervals you can probably do linear time (haven’t thought about it).
In your update you seem to say John R’s proposed algorithm is recursive, which in fact it is not. John R’s algorithm is the following:
For each 1 entry in the matrix, delete the row and column containing this entry. Interpret the smaller matrix as a biadjacency matrix, and search for a perfect matching in the bipartite graph that corresponds to this matrix. (I.e., not “recurse” as you write in your update.)
If a perfect matching exists for all 1s, then the matrix is an ormat, otherwise it is not.
This algorithm is easily seen to be polynomial time: the running time is at most the number of ones in the matrix (which is at most n^2) times the running time of a perfect matching algorithm.
For completeness’ sake here is also the correctness: If for every 1-entry in the matrix a perfect matching is found, then or-ing the matrices corresponding to these perfect matchings gives the orginal ormat: we know that for every 1-entry there is a perfect matching that has a one in that position, and for every 0-entry we know that these will never be included in any perfect matching.
If for some 1-entry a perfect matching cannot be found, then that means there does not exist a ranking that has the corresponding element in the corresponding position (because otherwise this ranking would give you the perfect matching that you are looking for).
Let me rephrase that “really good question” you attributed to me yesterday: The permanent tells us the maximum number of different permutations that can be OR-summed to produce a given ormat, but what is the corresponding minimum number? Also, in how many different ways can the minimum be achieved?
To go a little further, let p denote the permanent and m denote the minimum for a given ormat A, let P be the (maximal) set of all permutations whose OR-sum is A (so |P|=p), and let M1, M2, …, Mr be all the different minimal sets (meaning |Mi|=m for i=1,…,r) with OR-sum A. Obviously the union of the Mi’s is contained in P, but is it necessarily equal to P?
It is out:
http://graduate-school.phds.org/rankings/mathematics
http://graduate-school.phds.org/rankings/computer-science
Math:
1-4 Princeton University
1-3 University of California-Berkeley
2-5 Harvard University
2-6 New York University
4-9 Stanford University
4-12 University of Michigan-Ann Arbor
4-11 Yale University
5-11 Massachusetts Institute of Technology
5-16 Pennsylvania State University-Main Campus
6-15 University of Wisconsin-Madison
8-28 University of California-Los Angeles
9-25 Columbia University in the City of New York
Computer Science:
1-2 Stanford University
2-4 Princeton University
2-5 Massachusetts Institute of Technology
3-6 University of California-Berkeley
3-10 Carnegie Mellon University
5-12 Cornell University
4-16 University of Illinois at Urbana-Champaign
5-14 University of North Carolina at Chapel Hill
6-16 University of California-Los Angeles
6-18 University of California-Santa Barbara
Odd: Stanford has to be #1 since there aren’t any others…