
From the Associated Press, via the New York Times:
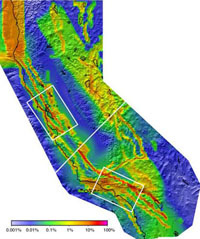
LOS ANGELES (AP) — California faces an almost certain risk of being rocked by a strong earthquake by 2037, scientists said in the first statewide temblor forecast.
New calculations reveal there is a 99.7 percent chance a magnitude 6.7 quake or larger will strike in the next 30 years. The odds of such an event are higher in Southern California than Northern California, 97 percent versus 93 percent.
I read this report with a certain sense of wonder. What impressed me was not the prediction itself; it’s not the first time I’ve heard that the Big One is coming. What took me by surprise was the level of mathematical sophistication that we can now take for granted in readers of the morning newspaper. No more do we have to worry that people will add up 97 percent and 93 percent to get 190 percent. Evidently, we’ve reached a state of universal numeracy, where everyone knows how to combine probabilities, and there’s no need to explain the calculation. We don’t even need to remind anyone that when we compute 1 – (1 – p)(1 – q), or p + q – pq, we are assuming that p and q represent probabilities of statistically independent events; everybody knows that. And everybody understands that in this context “a chance of a quake” really means “a chance of at least one quake.”
I guess the only place where we might still stumble is in actually doing the arithmetic. My calculator tells me the number is 99.8 percent, not 99.7.
A further note: The original report on which the news item is based leaves me even more perplexed. The probability model adopted in the forecast is explained as follows:
The simplest assumption is that earthquakes occur randomly in time at a constant rate; i.e., they obey Poisson statistics. This model, which is used in constructing the national seismic hazard maps, is “time independent” in the sense that the probability of each earthquake rupture is completely independent of the timing of all others. Here we depart from the… conventions by considering “time-dependent” earthquake rupture forecasts that condition the event probabilities… on the date of the last major rupture. Such models… are motivated by the elastic rebound theory of the earthquake cycle…; they are based on stress-renewal models, in which probabilities drop immediately after a large earthquake releases tectonic stress on a fault and rise as the stress re-accumulates due to constant tectonic loading of the fault.
In other words, it doesn’t sound as though the assumption of independence is even approximately satisfied. I must be missing something. The 99.7 percent combined probability is mentioned in the executive summary of the report, but I found no explanation of how that number was calculated.
Perhaps I shouldn’t worry so much. I live thousands of kilometers away in a zone of seismic serenity.
Update, several hours later: After reading a little more carefully, I think the report does assume that all possible earthquake sites are independent. At each site the probability of an event is a function of time, but it is independent of probabilities at other sites. Thus calculating a joint probability for the northern and southern parts of the state does seem to be a valid operation. And the distinction between “exactly one” and “at least one” doesn’t really enter into the matter either. That’s because the model is only valid until the next major earthquake occurs; after that, all bets are off, since the time-dependent probabilities have to be recalculated.
If this interpretation of the model is correct, I think the way the result is expressed is somewhat misleading. To say there’s a 97 percent chance in Socal and a 93-percent chance in Nocal implies there’s a high probability (90.2 percent) of seeing both events in the course of the 30-year period. But the model is no longer valid after the first quake.
I wonder if there isn’t a better way to express the concept at the heart of this story. Qualitatively, it’s easy enough to grasp: In the next 30 years there will almost certainly be a major earthquake somewhere in California, and the event is more likely to happen in the southern part of the state than in the northern part. Putting this into numbers is somewhat tricky—or at least I’ve had a lot of trouble with it. Having finally surrendered to the computer and performed a Monte Carlo simulation, I come up with this statement: There’s a 99.8 percent chance that the next major California earthquake will happen by 2037. If indeed such a quake occurs, the odds are about 57 to 43 it will hit in Southern California.
If they were independent, it would be 99.8%. If they were negatively correlated, it would be more (up to 100%). Since it is less, they must be positively correlated—which is counterintuitive. A simpler explanation is just that the numbers have been rounded.
There probably is some correlation since aftershocks are fairly frequent. Actually even if you are 30 miles away, this is not that significant.
I’ve been doing some reading on computational complexity, and in math brain the statement “1 – (1 – p)(1 – q), or p + q – pq” would zing by unnoticed, but in computer brain it scans as “he’s replaced 3 subtractions and 1 multiplication with 1 addition, 1 subtraction, and 1 multiplication”. It has given me an appreciation for the (unnamed?) discoverer of the distributive law.
Hmm. Math brain, computer brain…. There’s also logic brain. I find the formula 1 – (1 – p)(1 – q) much more congenial, and more useful in practice, because it embodies a simple Boolean equivalence: “one or the other or both” is the same as “not neither.” Understanding the formula p + q – pq in the same intuitive way requires a tad more thought — and I have so little of that to spare! But perhaps there are people who have the opposite response?
I find it easier with the second formula. I think that “p or q but not (p and q)” is more naturally translated as “p + q - pq” where: “or = +” , “not = -” and “and=product”. I find it difficult to “see” the other formula in this simple way. Anyway, two ways to do the same thing are better than one.
Inclusion, exclusion.
@Seb: That mapping between logical and arithmetical operators is appealing, but it always seems to lead me astray.
The logical expression “p or q but not (p and q)†corresponds to the exclusive or relation. The mathematical expression “p + q - pq†calculates something else — something that, translated into the language of logic, corresponds to the inclusive or. Think of a Venn diagram drawn in a square of unit area and containing two overlapping blobs labeled p and q. Following the logical formula “p or q but not (p and q)†we color p and we color q but then we erase the area of overlap, leaving p xor q. Whereas “p + q - pq†tells us to take the area of p, add the area of q, then subtract the area of overlap. But the result of this process is not p XOR q; it’s p OR q — the area of the square occupied by either p or q or both. The formula for the area of p XOR q would be p + q - 2pq.
Which is why I always lean toward the “negative” formula, 1 – (1 – p)(1 – q).
The real problem with Seb’s interpretation is he doesn’t say what “but” translates to. It seems to me it’s a synonym here for “and”, but (and?) “(p or q) and not (p and q)” translates to (p + q)(1 - pq). The closest one can get is to rewrite p + q - pq as p + q(1-p), which corresponds to “p or (q and not p).”
One virtue of the “negative” formula 1 - (1 - p)(1 - q) is that that form makes it easy to see that the result is less than (or equal to) 1, which is less clear from the p + q - pq formula.
Thank you Brian and Barry. I want to say that “but” translates into whatever is needed to make my statement right (ja!). Now seriously, are you trying to convert me to a negative formula follower? I’m starting to see its “naturality”. Since “p” includes “pq” and “q” includes “pq” substracting “pq” does the job. The sentence should be “p or q or both (but not both more than once!)”. Venn diagrams are so simple and so clear, much easier to understand than these words.
Regarding:
=========================
To say there’s a 97 percent chance in Socal and a 93-percent chance in Nocal implies there’s a high probability (90.2 percent) of seeing both events in the course of the 30-year period. But the model is no longer valid after the first quake.
=========================
Actually, the model isn’t valid for predicting another earthquake in the same general area. For the most-part, NoCal and SoCal are far-enough apart that the changes in stresses due to an earthquake in SoCal, wouldn’t hugely change the probability of an earthquake in NoCal.
For example, the Loma Prieta and Northridge earthquakes each significantly affected the chances of another large earthquake in the SF and LA areas, respectively. That’s because they changed the stresses in the immediate areas- relieving stress at/near the epicenter, but increasing it elsewhere in the area. The further away one gets, the less effect there is on the likelihood of another earthquake- there are simply too many other modifiers in between.
If you think of a convention center full of people milling around, one person falling over will significantly affect the possibility of another person falling over in that immediate area. However, because of booths, moving people, etc., it’s highly unlikely that one person falling over on THIS side of the convention center, will cause another person to fall over way OVER THERE. :-)