Factoidal Facts
by Brian Hayes
Published 16 April 2007
The May-June issue of American Scientist has been out for a week or so. My “Computing Science” column talks about a curious randomized version of the factorial function, which for lack of a better name I’ve called a factoidal function. I encourage everyone to rush right out and read all about it, but that’s not my only reason for posting this note here. I also have to report that in my discussion of factorials and factoidals, there’s at least one point where I have strayed from the factual.
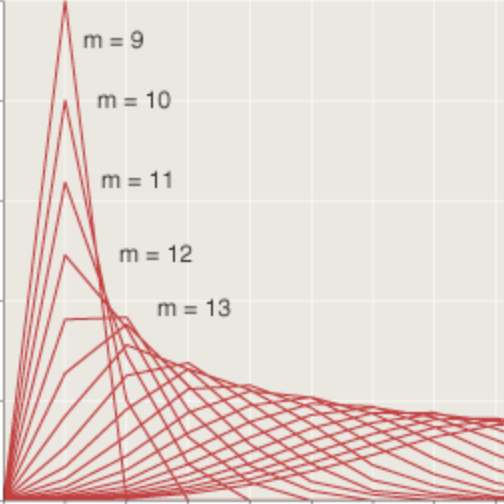
Here is the central figure in the article:

It shows the “average” value of factoidal(10) as a function of the size of the sample over which the average is calculated. (To understand why the “average” depends on the sample size (and therefore isn’t really an average), please see the article.) Both in the caption that accompanies this figure and in the text of the article, I describe the graph as showing exponential growth. Ernst Zinner of Washington University in St. Louis writes to point out that the description is incorrect. Although it’s true that the dependent variable (the value of the “average”) increases exponentially, so does the independent variable (the sample size). Consequently, the relation between the variables is characterized not by an exponential function but by a power law. This concept is introduced later in the article, but my description of the figure unfortunately sows confusion. My thanks to Zinner for setting me straight.
Responses from readers:
Please note: The bit-player website is no longer equipped to accept and publish comments from readers, but the author is still eager to hear from you. Send comments, criticism, compliments, or corrections to brian@bit-player.org.
Publication history
First publication: 16 April 2007
Converted to Eleventy framework: 22 April 2025


The article contains another passage I consider to be misleading. After reporting that the arithmetic mean of the logs converges, you say that “Logarithms reduce multiplication to addition. Essentially, then, taking the logarithm of the n? values converts the factoidal process into the corresponding triangular number calculation.” This is only true in a very broad sense of “essentially,” because the log of the factoidal is a sum of logs, which is not the sort of sum the triangular number calculation calculates. The real reason why “the success of this strategy does not come as a surprise” is because the arithmetic mean of logs is the same as the log of the geometric mean — and having shown that the geometric mean converges, we shouldn’t be surprised that its log does as well. The closest you seem to come to expressing this relationship between the two kinds of mean is to say that “logarithms are also at work behind the scenes in computing the geometric mean” — a statement that doesn’t seem calculated to enlighten many readers.
Thanks for the clarification; always appreciated.
I think this sentence is a little unclear: “Of course we could just as easily count up from 1 to n; the commutative law guarantees that the result will be the same.”
Consider the following three forms of factorial:
1) for x in 1 upto n: product := product * x
2) for x in n downto 1: product := x * product
3) for x in n downto 1: product := product * x
Proving the equivalence of 1) and 2) requires the associative law; proving the equivalence of 2) and 3) requires the commutative law. (Proving the equivalence of 1) and 3) requires both.) Note that proving the equivalence of upward and downward counting requires either the associative law, or both (depending on the exact form of factorial you use); but cannot be done using only the commutative law.
On the contrary, the sentence is perfectly clear. Wrong, but clear. Carl Witty is correct that the associative law is needed to prove that any permutation of the factors yields the same product.
It’s amusing to count the number of times the associative law is invoked in converting 1*(2*(3*(…*n))…) to ((..(1*2)*3)*…)*n. For example,
1*(2*(3*4)) = 1*((2*3)*4) = (1*(2*3))*4 = ((1*2)*3)*4
invokes the associative law 3 times, and
1*(2*(3*(4*5))) = 1*(2*((3*4)*5)) = 1*((2*(3*4))*5) = 1*(((2*3)*4)*5) = (1*((2*3)*4))*5 = ((1*(2*3))*4)*5 = (((1*2)*3)*4)*5
invokes it 6 times. The resulting sequence for n=3,4,5,… is 1,3,6,10,… Did someone mention triangular numbers?
Have you tried replacing the Stop at 1 with a Stop at N in your algorithm?
The results might be surprising.
Aaron Sheldon’s question brings to light an ambiguity in the original statement of the algorithm. We are forming the product of random numbers drawn from the set {1..n} until some special sentinel value, x, turns up. What’s not clear is whether or not we should include x in the product. The answer doesn’t matter in the original case, where x=1, but it does make a difference when x=n.
I think I know what ought to happen in the additive analog of the factoidal function—the “randomized triangular numbers”—when we set x=n instead of x=1. If the sentinel x is included in the sum, then it shouldn’t matter what value we choose as the sentinel. On average, the process ends after we’ve selected n numbers with an average value of (n+1)/2, and so the expected sum will be (n(n+1))/2 in any case. If the sentinel is n and we don’t include it in the sum, then on average we’re selecting n–1 numbers with an average value of n/2, and the expected sum is reduced to ((n–1)n)/2.
But what happens in the case of the multiplicative factoidal function, where we’re doing products instead of sums and the mean is undefined? Is the analogy with triangular numbers a useful guide here? Specifically, supposing the sentinel is included in the product, is the outcome still the same no matter what value is chosen as sentinel? Here are two hand-waiving arguments on opposite sides:
Choose your rationale!
Here’s another small entertainment for a Sunday afternoon. Let’s define a new factoidal-like function where we again choose numbers at random from 1 to n, but now, before taking the product, we replace some of the numbers by their reciprocals. Specifically, with probability 1/2 each number x is transformed into 1/x. Equivalently, we can imagine we are building a fraction where each number is randomly assigned to the numerator or the denominator. (Maybe we should call this the “fractoidal” function.)
In some respects fractoidal(n) illustrates the problem of heavy-tailed distributions even more dramatically than the original factoidal function. In the fractional case, the geometric mean is not only well-defined, it has the invariant value 1 no matter what the value of n. But the arithmetic mean still diverges.
I brought up the question because I actually tried to calculate the frequency of numbers, via products of the geometric distribution, and prime factorization. This is because the power with which each integer is raised is distributed geometrically. The reason I was working all this out was to calculate the coefficient in the power law fit you gave, and also to come up with a memory efficient version of the alorithm.
What I noticed was that the divergence in the mean occured because of the multiple multiplications by the largest number. If that was cut short then the mean didn’t diverge but instead is something like:
((N-1)^(N-1))/((N-1)!)
1/N is the value of the parameter in the geometric distribution at which the products diverge. If the parameter is less than 1/N (favouring smaller exponents) then the product converges. With the product going as the ratio of Gamma functions.
Fat tailed distributions are also interesting because they are vectors for which the linear operators of quantum mechanics are discontinuous. My favourite square integrable example is
1/(sqrt(2pi)(x+i))
because the position operator diverges at this point in the Hilbert Space.