What a world we live in. It seems there are places on this planet that are wired well enough to support internet commerce, yet where people are poor enough that solving CAPTCHAs for 50 cents per thousand is an economically appealing proposition. That’s roughly three hours of work for half a buck—minus whatever it costs the worker for internet access.
I have learned this from a fascinating paper (PDF) by Stefan Savage and his colleagues at the University of California, San Diego. The Savage group studied the CAPTCHA-solving economy in a very direct way—by participating in it, both as customers and as workers.
 CAPTCHAs are meant to thwart computer programs that sign up for bogus email accounts in order to send spam, or that post spammy comments on forums or blogs like this one. Transcribing the distorted and obscured text is a task that’s supposed to be easier for people than for machines. The spammers’ first response to CAPTCHAs was to write programs that solve them algorithmically, but in this arms race the advantage is with the white hats. Deploying a new style of CAPTCHA is quick and cheap; developing a new solver for that CAPTCHA is slow and costly. And so the spammers have turned to human solvers.
CAPTCHAs are meant to thwart computer programs that sign up for bogus email accounts in order to send spam, or that post spammy comments on forums or blogs like this one. Transcribing the distorted and obscured text is a task that’s supposed to be easier for people than for machines. The spammers’ first response to CAPTCHAs was to write programs that solve them algorithmically, but in this arms race the advantage is with the white hats. Deploying a new style of CAPTCHA is quick and cheap; developing a new solver for that CAPTCHA is slow and costly. And so the spammers have turned to human solvers.
A CAPTCHA that gets caught up in this illicit trade is likely to take quite a globe-girdling journey in a matter of seconds. The images are typically generated by a service such as reCAPTCHA (now owned by Google), and embedded in the sign-up form or comment form of a web site. The spammer’s software (such as GYC Automator) scrapes the image from the page and forwards it to a front-end system, which aggregates CAPTCHA-solving requests and collects payment from the spammers. The image is then passed on to a back-end operation, which marshals the services of individual solvers and distributes payments to them. The solver sees the image on a simple web form and types the transcription into a text box. If all goes well (from the spammer’s point of view), a correct solution comes back within the 30 seconds or so that most pages allow for solving the puzzle.
Some other findings of the Savage study:
- The piece-work rate offered to solvers has fallen steadily, from $10 per thousand in 2007 to the present level of $0.50 to $0.75.
- The price paid by spammers is higher, of course, and also variable. Typical current rates are in the range of $1 to $2 per thousand, but some services charge as much as $20.
- Most of the services tested by Savage et al. were fast and accurate, solving 85 to 90 percent of the CAPTCHAs correctly, with a median response time of 14 seconds.
- By gradually raising the rate of CAPTCHA submissions until responses slowed and additional work was refused, Savage et al. estimated the size of the workforce. The largest outfits seemed to have at least 400 to 500 workers online at once.
- In an attempt to learn where the solvers live, Savage et al. sent out specially fabricated CAPTCHAs with images of words in various languages. They reasoned that accuracy would be highest in the worker’s native language. If this hypothesis is correct, many of the CAPTCHA solvers are fluent in Chinese, Russian or Hindi. But one organization showed exceptional linguistic versatility, even solving challenges in Klingon.
- By offering their services as solvers, the Savage group were able to gather some statistics on what kinds of CAPTCHAs are flowing through the dark side of the internet. Microsoft CAPTCHAs (used on the Hotmail sign-up form) were the most popular. Others seen frequently included reCAPTCHA images and products of several Russian-language services.
The paper includes a discussion of the ethics and legality of this project. Is it acceptable, even for research purposes, to abet the unsavory activities of spammers? The Savage group concluded that acting as buyers of the service caused little harm because the purchased solutions were never used to register fraudulent accounts or post messages. But working as solvers was more troubling, because the solutions they provided would indeed be used to further the aims of spammers.
To sidestep this concern, we chose not to solve these CAPTCHAs ourselves. Instead, for each CAPTCHA one of our worker agents was asked to solve, we proxied the image back into the same service via the associated retail interface. Since each CAPTCHA is then solved by the same set of solvers who would have solved it anyway, we argue that our activities do not impact the gross outcome.
It’s an ingenious dodge, even if it doesn’t put one’s mind totally at ease about the ethical question. (Suppose we were studying murder-for-hire instead of CAPTCHAs-for-hire—would the same reasoning be acceptable?) Ethics aside, however, the tactic of recirculating work requests back into the same system raises other curious issues.
For one thing, it suggests a way of measuring the size of the CAPTCHA-solving enterprise. We could run a capture-recapture experiment (or should I say CAPTCHA-reCAPTCHA?). Suppose we never solve a CAPTCHA ourselves, but we make a record of each image as it arrives, before we dump it back into the work stream. From the fraction of recirculated CAPTCHAs that come back to us at least once more we could estimate the total size of the work flow. Of course this assumes that the stream of CAPTCHAs is well-mixed. It also assumes there is no one else out there recirculating CAPTCHAs.
This last caveat leads to an interesting economic question. As noted above, retail prices for CAPTCHA-solving vary over a wide range, from about $1 per thousand to $20 per thousand. This price spread, and the fact that it’s technically feasible to route a CAPTCHA through the system more than once, suggests a major arbitrage opportunity. We can set up a high-price CAPTCHA service and farm out all the actual work to low-price competitors. In a free economy—and what economy could be freer of regulation than a criminal one?—that situation is not supposed to endure.
• • •
While I’m on the subject of spam, I’ll take the opportunity to update my own running tally.
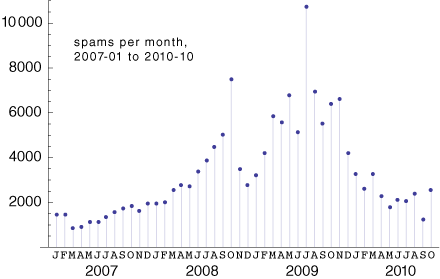
Activity in my inbox has been unexciting since my last report. Spam volume is still well below the peaks of mid-2009, but on the other hand there’s not much support for the fond notion that spam is on the verge of extinction. News reports have suggested that the shutdown of a Russian web site called SpamIt.com, allegedly run by Igor Gusev, caused a sharp dropoff in the global spam rate in September. And indeed my September intake was the smallest since June of 2007. But the chronology isn’t quite right. SpamIt was closed on September 27, so that event should have depressed the October numbers more than those for September. My spam receipts rebounded in October. About 40 percent of the October spam messages use a Russian-language encoding.
Update 2010-11-28: Peter G. Neumann’s RISKs list has an item about criminal charges against the operators of Wiseguy Tickets, whose business model involved solving CAPTCHAs in bulk. By circumventing the CAPTCHAs, they supposedly jumped to the head of the line at Ticketmaster and scooped up 11,984 Hannah Montana concert tickets.
The RISKs item cites a Wired article by Kim Zetter, which seems to be based mainly on the indictment (PDF) filed in the U.S. District Court of New Jersey. Here’s how the Wiseguys did it, according to the indictment:
11. It was further part of the conspiracy that to enable the CAPTCHA Bots to purchase tickets automatically, Wiseguys:
a. Downloaded hundreds of thousands of possible CAPTCHA Challenges from reCAPTCHA. To obtain these CAPTCHA Challenges anonymously, Wiseguys wrote a computer script that disguised the origin of the download requests by impersonating would-be users of Facebook, which also subscribed to reCAPTCHA.
b. Created an “Answer Database” by having its employees and agents read tens of thousands of CAPTCHA Challenges (or listen to audio CAPTCHA Challenges) and enter the answers into a database of File IDs and corresponding answers.
12. It was further part of the conspiracy that, during the ticket-buying process, instead of “reading” a CAPTCHA Challenge, the CAPTCHA Bots identified the CAPTCHA Challenge’s File ID. The CAPTCHA Bots then instantly compared the CAPTCHA Challenge’s File ID against the Answer Database, looking for a matching File ID. If the CAPTCHA Bots found a matching File ID, it immediately and automatically transmitted the pre-typed answer to that CAPTCHA Challenge to the Online Ticket Vendors’ website. This process took place in a fraction of a second, much faster than a human user could respond to a typical CAPTCHA Challenge.
I’m having trouble making sense of this. The scheme would work only if reCAPTCHA is repeatedly sending out the same image, linked to the same file ID, and reusing images often enough that if you save a few hundred thousand of them, you’ll have a good chance of finding any new challenge already present in your database. Surely it’s not that easy?
It’s true that reCAPTCHA (unlike other CAPTCHA services) must gather multiple solutions for some images. That’s because of their aim of using the labor of solvers to proofread scanned texts. Each reCAPTCHA includes two words. The solution for the “control word” is known in advance and is used to authenticate the solver; the solution offered by the solver for the “unknown word” becomes a candidate reading of that word in the OCR process. Multiple solvers must agree on the same reading of the unknown word before the transcription is accepted. Thus each unknown word is presented more than once. But is it always paired with the same control word? And with the same file ID?
The reCAPTCHA folks are pretty savvy about such weaknesses. A list of guidelines on their web site includes this paragraph:
Script Security. Building a secure CAPTCHA is not easy. In addition to making the images unreadable by computers, the system should ensure that there are no easy ways around it at the script level. Common examples of insecurities in this respect include: (1) Systems that pass the answer to the CAPTCHA in plain text as part of the web form. (2) Systems where a solution to the same CAPTCHA can be used multiple times (this makes the CAPTCHA vulnerable to so-called “replay attacks”).
So if the reCAPTCHA programmers are taking their own advice, the Wiseguys should have been out of luck. And yet we have the evidence of those 11,984 Hannah Montana tickets. What’s the story?