The March–April American Scientist has been out for a couple of weeks. My “Computing Science” column looks at the future of scientific illustration in a world where we do most of our reading not on paper but on a screen of some kind—a screen that has a computational engine behind it.
My hope for those future illustrations is that they won’t just sit on the page looking pretty. They’ll do stuff. They’ll make good use of the available computing machinery. They’ll invite the reader to interact and explore. Below is my attempt to give an example of the kind of illustration I have in mind. It’s an interactive version of the familiar population pyramid, based on data from the U.N. and built with HTML, CSS, SVG and the d3.js JavaScript library from Michael Bostock. Please play.
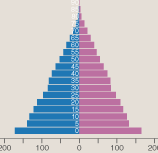
I’m optimistic and enthusiastic about the digital future of science publishing. The digital present is another matter. One indicator of how far we still have to go is that some of you have no idea what that population-pyramid illustration is supposed to look like, because it doesn’t appear on your screen. If you’re reading this with an older web browser, you may see a static placeholder illustration or an error message or nothing at all. If you’re reading the RSS feed, I offer my apologies, but there’s nothing I can do to help.
Apart from problems of accessibility and compatibility, there’s a deeper issue I want to address here. If the aim is to enhance the literature of science, we have to keep in mind that very little of that literature takes the form of HTML, CSS, SVG and JavaScript. Almost all journal articles and preprints are distributed as PDFs. I have no idea how to make my little animated population pyramid work inside a PDF.
“PDF” stands for Faux Paper Document. PDFs look just like their printed prototypes, with all the typographical niceties—justification, hyphenation, kerning of letter pairs, ligatures. It’s as if the words and pictures had been skimmed off the page and pasted onto the screen (which is in fact pretty close to how the process works). This fidelity to the print tradition follows directly from the history of PDF: It was an outgrowth of PostScript, which was an outgrowth of InterPress, which was developed as software for use in the printing trades. The successful imitation of paper documents is a laudable achievement. As a culture, we have several hundred years of effort invested in learning how to present information effectively and attractively on the printed page; we shouldn’t let that go to waste. However, using a multigigahertz, multigigabyte computing machine as a standin for a sheet of dried cellulose seems a bit of a waste. It’s rather like early printers striving to reproduce the stylistic quirks of scribes writing with quill pens.
HTML can’t match the designerly refinement of PDF, but it is more versatile, livelier, and even playful. HTML documents do tricks. Where PDF is for the suits, HTML/CSS/JavaScript is the home of hackers.
But, again, few scholarly papers are published in HTML. There are a number of reasons for this, but to me the one that seems most salient is a certain lack of thinginess. In my column I write:
Why do authors and readers prefer PDFs for this kind of publication? One factor may be this: A PDF is something you possess. You download it from a server, give it a name, store it in a folder. It’s yours; it stays put. A website built out of HTML has a different character. It’s not a thing you own but a place you visit. You can’t take it home with you—although perhaps you can send a postcard or keep a small souvenir in the form of a bookmark.
“HTML” is an abbreviation for Highly Temporary Markup Language.
If we take this view seriously, then what the world needs is a way to encapsulate HTML documents so that they become first-class, discrete objects—things you can keep, rename, pass around, copy, delete, annotate, modify. For years I thought that this capability should be built into web browsers—that you should be able to press a button to download and store a fully functional and totally self-contained local copy of any web page. My favorite browser of the 1990s, called iCab, came pretty close to this ideal, but for many modern web pages the client-side approach is either unworkable or undesirable. With pages that rely on technologies such as AJAX, it’s not possible to make a fully self-sufficient local copy. And often there are page elements you don’t really want to include in your private copy, such as navigational menus and “Like” buttons and comment forms.
An alternative strategy is to let the author of the HTML document take responsibility for creating a downloadable, autonomous version, with content tailored for that environment. A technology for doing this sort of thing already exists: It’s the EPUB format used by various eBook readers. An EPUB document is essentially a collection of HTML files, CSS stylesheets and various forms of metadata wrapped up in a zip archive. SVG is supported, along with MathML. The 3.0 standard says JavaScript is also acceptable, but that statement is accompanied by a list of warnings that sound like the side-effect disclosures in a pharmaceutical ad.
Apple’s new iBooks Author program also produces some kind of encapsulated HTML, but of course it works only in the Apple sector of the universe. If you’d rather affiliate with a different proprietary dominion, there’s something called CDF from Wolfram Research. (The initials stand for “Conrad’s Document Format.”)
Still another approach would be to stick with PDF but make it more fun. According to the PDF 1.7 specification (which, as you might guess, comes in the form of a PDF), a JavaScript compiler is supposed to be available within PDF documents, and Adobe has an Acrobat JavaScript API document. But as far as I can tell scripting is commonly used only for validating forms and playing slideshows.
The latest version of Acrobat does have a pretty cool interactive viewer for three-dimensional objects. Three years ago Alyssa Goodman and her colleagues at Harvard published a paper in Nature that made use of that viewer. This was apparently the first scientific publication to include a 3D PDF. I don’t know of another example since. And I have never seen any other kind of interactive graphics embedded in a PDF.
For more on all this, I invite you to read my column in the format of your choice: good old-fashioned paper, fine artisanal HTML (with whiz-bang JavaScript graphics), or the pixelated form of paper we call PDF.