PDF vs. HTML
by Brian Hayes
Published 18 February 2012
The March–April American Scientist has been out for a couple of weeks. My “Computing Science” column looks at the future of scientific illustration in a world where we do most of our reading not on paper but on a screen of some kind—a screen that has a computational engine behind it.
My hope for those future illustrations is that they won’t just sit on the page looking pretty. They’ll do stuff. They’ll make good use of the available computing machinery. They’ll invite the reader to interact and explore. Below is my attempt to give an example of the kind of illustration I have in mind. It’s an interactive version of the familiar population pyramid, based on data from the U.N. and built with HTML, CSS, SVG and the d3.js JavaScript library from Michael Bostock. Please play.
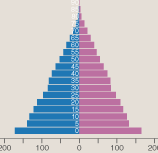
I’m optimistic and enthusiastic about the digital future of science publishing. The digital present is another matter. One indicator of how far we still have to go is that some of you have no idea what that population-pyramid illustration is supposed to look like, because it doesn’t appear on your screen. If you’re reading this with an older web browser, you may see a static placeholder illustration or an error message or nothing at all. If you’re reading the RSS feed, I offer my apologies, but there’s nothing I can do to help.
Apart from problems of accessibility and compatibility, there’s a deeper issue I want to address here. If the aim is to enhance the literature of science, we have to keep in mind that very little of that literature takes the form of HTML, CSS, SVG and JavaScript. Almost all journal articles and preprints are distributed as PDFs. I have no idea how to make my little animated population pyramid work inside a PDF.
“PDF” stands for Faux Paper Document. PDFs look just like their printed prototypes, with all the typographical niceties—justification, hyphenation, kerning of letter pairs, ligatures. It’s as if the words and pictures had been skimmed off the page and pasted onto the screen (which is in fact pretty close to how the process works). This fidelity to the print tradition follows directly from the history of PDF: It was an outgrowth of PostScript, which was an outgrowth of InterPress, which was developed as software for use in the printing trades. The successful imitation of paper documents is a laudable achievement. As a culture, we have several hundred years of effort invested in learning how to present information effectively and attractively on the printed page; we shouldn’t let that go to waste. However, using a multigigahertz, multigigabyte computing machine as a standin for a sheet of dried cellulose seems a bit of a waste. It’s rather like early printers striving to reproduce the stylistic quirks of scribes writing with quill pens.
HTML can’t match the designerly refinement of PDF, but it is more versatile, livelier, and even playful. HTML documents do tricks. Where PDF is for the suits, HTML/CSS/JavaScript is the home of hackers.
But, again, few scholarly papers are published in HTML. There are a number of reasons for this, but to me the one that seems most salient is a certain lack of thinginess. In my column I write:
Why do authors and readers prefer PDFs for this kind of publication? One factor may be this: A PDF is something you possess. You download it from a server, give it a name, store it in a folder. It’s yours; it stays put. A website built out of HTML has a different character. It’s not a thing you own but a place you visit. You can’t take it home with you—although perhaps you can send a postcard or keep a small souvenir in the form of a bookmark.
“HTML” is an abbreviation for Highly Temporary Markup Language.
If we take this view seriously, then what the world needs is a way to encapsulate HTML documents so that they become first-class, discrete objects—things you can keep, rename, pass around, copy, delete, annotate, modify. For years I thought that this capability should be built into web browsers—that you should be able to press a button to download and store a fully functional and totally self-contained local copy of any web page. My favorite browser of the 1990s, called iCab, came pretty close to this ideal, but for many modern web pages the client-side approach is either unworkable or undesirable. With pages that rely on technologies such as AJAX, it’s not possible to make a fully self-sufficient local copy. And often there are page elements you don’t really want to include in your private copy, such as navigational menus and “Like” buttons and comment forms.
An alternative strategy is to let the author of the HTML document take responsibility for creating a downloadable, autonomous version, with content tailored for that environment. A technology for doing this sort of thing already exists: It’s the EPUB format used by various eBook readers. An EPUB document is essentially a collection of HTML files, CSS stylesheets and various forms of metadata wrapped up in a zip archive. SVG is supported, along with MathML. The 3.0 standard says JavaScript is also acceptable, but that statement is accompanied by a list of warnings that sound like the side-effect disclosures in a pharmaceutical ad.
Apple’s new iBooks Author program also produces some kind of encapsulated HTML, but of course it works only in the Apple sector of the universe. If you’d rather affiliate with a different proprietary dominion, there’s something called CDF from Wolfram Research. (The initials stand for “Conrad’s Document Format.”)
Still another approach would be to stick with PDF but make it more fun. According to the PDF 1.7 specification (which, as you might guess, comes in the form of a PDF), a JavaScript compiler is supposed to be available within PDF documents, and Adobe has an Acrobat JavaScript API document. But as far as I can tell scripting is commonly used only for validating forms and playing slideshows.
The latest version of Acrobat does have a pretty cool interactive viewer for three-dimensional objects. Three years ago Alyssa Goodman and her colleagues at Harvard published a paper in Nature that made use of that viewer. This was apparently the first scientific publication to include a 3D PDF. I don’t know of another example since. And I have never seen any other kind of interactive graphics embedded in a PDF.
For more on all this, I invite you to read my column in the format of your choice: good old-fashioned paper, fine artisanal HTML (with whiz-bang JavaScript graphics), or the pixelated form of paper we call PDF.
Responses from readers:
Please note: The bit-player website is no longer equipped to accept and publish comments from readers, but the author is still eager to hear from you. Send comments, criticism, compliments, or corrections to brian@bit-player.org.
Publication history
First publication: 18 February 2012
Converted to Eleventy framework: 22 April 2025



One obstacle toward self-contained thing-like web products is the business model problem. So much pressure seems to be heading toward online experiences, with data mining and ad- or subscription-based monetizing. From the producer’s side, letting people hold copies in hand is just not that attractive.
One of the problems with the HTML format is that it’s easy to hijack for purposes that are not authorial. In fact, I find your article much easier to read in the PDF format, because my screen is not full of visual clutter that has nothing to do with the content. (The menu bar is not the most important part, for example.) Nor do I have to keep pushing the Next button (whose location is not standardized) to retrieve the next dollop; I can continuously scroll it with the mouse wheel. Admittedly, the Readability bookmarklet and the AutoPager plug-in help quite a lot with both of these issues.
One illustration what computer viewing can do for a scientific paper is here: http://worrydream.com/ScientificCommunicationAsSequentialArt/
Sweet! It looks like I could make it to 2038 without too much trouble.
I assume my hover car will fall out of the sky due to Unix epoch bug.
Note to self: don’t use hover car until gmmktime() returns 2177481600
@Bryce: Thanks so much for the pointer to the fabulous web site of Bret Victor. This is work I wish I had known about before I started writing on the subject, but I didn’t. I am eager to explore all of it now that I know.
@John Cowan: At the risk of seeming disloyal to my publisher, I have to admit that I agree with your gripes. On the other hand, it seems a bit harsh to condemn an entire technology because of the infelicities of one web site. There are badly printed books, too, and ugly PDFs.
@Frank Ch. Eigler: Yes, but one can make the opposite argument too. One reason people are reluctant to pay for access to content on the web may be the feeling that no merchandise is changing hands. Apple’s experience with iOS suggests that people *will* pay when the content is packaged as something you can download and keep.
I have a confession to make: I have enjoyed the PDF versions of your articles for quite some time now, and I still have the experience of often choosing to read PDF versions of free online books rather than HTML versions, despite the disadvantages. But the advantages are obvious: the availability of interactivity and animation (as in your JavaScript-based population pyramid) is immense. It is unfortunate that we are still in a transitional period during which really good Web page design to rival that of print-oriented PDF is rare, but I hope this will change.
For the record, I did download the PDF version of your article as well as page through the HTML version. The HTML version is horribly formatted. I realize you have no control over how American Scientist formatted your content. I have no idea why they have no design sense on their Web site. Maybe they let it be so bad in order to discourage people from reading on the Web and instead buy the paper subscription. I realize there are some issues with incentives that need to be solved in the publishing world.
I think that you overestimate the benefits of interactivity and don’t address the costs. In most cases, the main benefit is *not* to enhance understanding, but is rather for entertainment. As you say, “Please play,” it can be fun to play with interactive gadgets. In science papers, not popular science, this is less of a benefit. Your population pyramid could have been illustrated well with a diagram with population curves overlaid on each other, and I myself would have preferred this—less fun to play with, but more information. For the vast majority of scientific papers, there is no benefit at all to interaction. Yes, there are exceptions, but they are not worth retooling around.
As to costs, the format is a huge problem. Paper lasts forever (once it is scanned to pdf :). Standard PDF will probably last forever. That is, unless Adobe manages to kill it by adding in more interactive features like 3D objects that are only supported by their terrible Reader software. Proprietary things like iBooks or CDF will often die in a few years. I don’t know how long a modern HTML page will last, with its CSS and Javascript. In the last generation, people used Flash for these features, and Flash will certainly be dead within ten years. Since companies like their proprietary formats, I think the problem will get worse in the future, not better.
To try to rebut myself, it seems like it should be possible to have a format that allows fallbacks to non-interactive versions if the interactive version should not work. So why doesn’t this happen? I think one problem is that the vendors creating these formats have incentives to keep it from happening. Adobe doesn’t want PDF to become an archival format, because they earn revenue from keeping it changing. Apple and others want each version to have new incompatibilities that force people to keep upgrading. Publishers do not want their eBooks to be usable in the future; they have learned from the music and movie industries that there is a lot of revenue to be earned by forcing people to upgrade their collections. Possibly scientists could create their own format in which archivability is an explicit goal—but there isn’t the scale there to get people to adopt it.
@John: Where to draw the line between essential explanatory illustration and ornamental frippery? Tastes differ. There’s a “sci vis” community that argues for the importance of interactive graphics not just for communicating results (or for entertaining the low-attention-span masses) but as part of the process of discovery. At the other end of the spectrum, there are geometers who claim that even ordinary diagrams are distracting and misleading; they want the proof and nothing but the proof. My own position is this: Even if you’re right that these graphic devices are more about fun than information, I’m going to err on the side of fun.
As to the other question you raise, about long-term survivability, I agree that it’s extremely troubling. I have a feeling that future generations may not thank us for some of the decisions we’re making today.
@Franklin Chen: I have to make the same confession: I too prefer the PDF. Right now it’s the clear choice. But I would argue that HTML has greater potential.
One problem is not that there is no standard way to save a webpage, but that there are too many: a folder with relative links, epub, mhtml, Mozilla archive format, Safari’s archive format, etc. It’s difficult to have confidence in one format, since it’s not clear which standard will be useful later.
Some uses of html, especially ones which really make use of large databases or communications, will never work as a stored document. On the other hand, ones which change their appearance dynamically but not their content should work fine as saved documents.
The most appropriate method might be for the author to prepare a saved file version, much like one does with pdf today.
Brian: I certainly don’t condemn an entire technology. Nevertheless, AS is not the only publisher to junk up their HTML versions of articles, and I can hardly think of a commercial publisher other than Baen Books that does not, in fact.
There is now a subset of PDF called PDF/A which is specifically intended for archival purposes. It’s an ISO standard. In particular, PDF/A documents do not depend on any fonts except embedded fonts, unlike more usual PDFs.
One concern I have with proprietary script formats is that they are non-standardized in web browsers, and possibly require plug-in support. I am not a fan of non-native support for any elements on a page. Kudos for offering an alternative to plug-in animation!
Also, please consider supporting the down arrow onfocus only so that when one scrolls with them, the animated-graph does not change. I saw the spot in the code and suggest checking for focus on the element before adding the handler and removing it onblur. Not to lose focus on the content, but just thought I would offer that up.
I see a lot in the code that I could learn from, thanks!
One reason for the popularity of PDF as compared to HTML based formats such as EPUB is the fact that it is currently very easy to create PDF documents, even including some degree of interactivity, while creating a nicely formatted HTML documents with interactive visualizations, and math expressions that will reliably display on all common web browsers is, as far as I can tell, very hard. Take as an example the article by Bret Victor on Small World Networks. I have pretty good idea how to produce something like that in PDF with pdfLaTeX or ConTeXt, but I wouldn’t even know where to start if I wanted to produce an HTML version like the one on the website.
Interesting discussion with some excellent points on both sides. The key to me is that a visitor has an option of viewing the PDF or the HTML. PDF is more difficult to make accessible than HTML and that’s an important consideration, especially for university Web sites.
For a neat example of a 3D, rotatable object in a pdf file, see
http://meshlab.sourceforge.net/
and scroll down to “ScreenShots”.
If you can generate a surface with, say, Mathematica, you can use (free) MeshLab to convert it to u3d format, then use (free) LaTeX to make a pdf file like the one shown on the MeshLab website.
More examples of pdf files with 3d objects in them can be found at http://asymptote.sourceforge.net/gallery/
About half of the files there have embedded 3d objects in them. Of course, you can only interact with the 3d object if you use adobe reader, otherwise you get a regular 2d version only.
It is another example of what I talked about earlier: pdf files are really easy to create, but there are very limited options for their viewing (in that I include accessibility problems, as well). HTML and related format are really easy to view, but hard to create.
As far as HTML vs. PDF is concerned, this is an article worth reading: Pettifer & al. - Ceci n’est pas un hamburger: modelling and representing the scholarly article - Learned Publishing, Volume 24, Number 3, July 2011 , pp. 207-220(14) - DOI: http://dx.doi.org/10.1087/20110309
And regarding 3D and other intereactive features in PDFs, this free scientific PDF-viewer should be checked out: Utopia Documents (http://utopiadocs.com)