
The average web site has links connecting it with 29 other sites. I came up with this number in the following way. A data set I’ve been playing with for a few weeks lists 43 million web sites and 623 million links between sites; the quotient of those numbers is about 14.5. Since each link has two ends, the per-site total of inbound plus outbound links is double the quotient.
Twenty-nine links is the average, but by no means is it a typical number of links. Almost half of the sites have four or fewer links. At the other end of the spectrum, the most-connected web site (blogspot.com) has almost five million links, and there are six more sites with at least a million each. The distribution of link numbers—the degree sequence—looks like this (both scales are logarithmic, base 2):
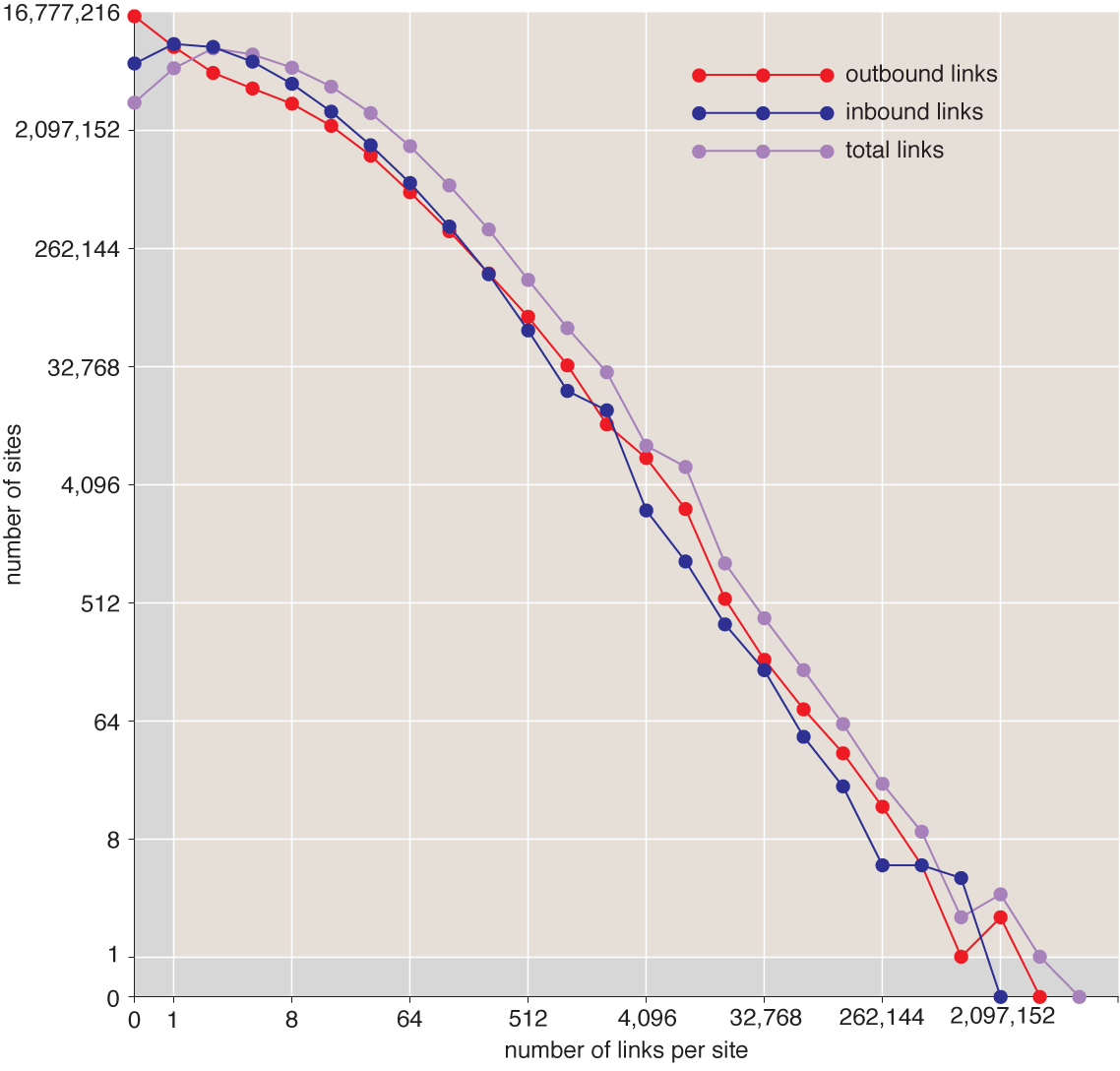
I want to emphasize that these are figures for web sites, not web pages. The unit of aggregation is the “pay-level domain”—the domain name you have to pay to register. Examples are google.com or bbc.co.uk. Subdomains, such as maps.google.com, are all consolidated under the main google.com entry. Any number of links from pages on site A to pages on site B are recorded as a single link from A to B.
The source of these numbers is the Web Data Commons, a project overseen by a group at the University of Mannheim. They extracted the lists of domains and the links between them from a 2012 data set compiled and published by the Common Crawl Foundation (which happens to be the subject of my latest American Scientist column). The Common Crawl does essentially the same thing as the big search engines—download the whole Web, or some substantial fraction of it—but the Common Crawl makes the raw data publicly available.
There are interesting questions about both ends of the degree sequence plotted above. At the far left, why are there so many millions of lonely, disconnected web sites, with just one or two links, or none at all? I don’t yet feel I know enough to tell the story of those orphans of the World Wide Web. I’ve been focused instead on the far right of the graph, on the whales of the Web, the handful of sites with links to or from many thousands of other sites.
From the set of 43 million sites, I extracted all those with at least 100,000 inbound or outbound links; in other words, the criterion for inclusion in my sample was \(\min(indegree, outdegree) \ge 100,000\). It turns out that just 112 sites qualify. In the diagram below, they are grouped according to their top-level domain (com, org, de, and so on). The size of the colored dot associated with each site encodes the total number of links; the color indicates the percent of those links that are incoming. Hover over a site name to see the inbound, outbound and bidirectional links between that site and the other members of this elite 112. (The diagram was built with Mike Bostock’s d3.js framework, drawing heavily on this example.)
Patience, please . . .
The bright red dots signify a preponderance of outgoing links, with relatively few incoming ones. Many of these sites are directories or catalogs, with lists of links classified by subject matter. Such “portal sites” were popular in the early years of the Web, starting with the World Wide Web Home at CERN, circa 1994; another early example was Jerry and David’s Guide to the World Wide Web, which evolved into Yahoo. Search engines have swept aside many of those hand-curated catalogs, but there are still almost two dozen of them in this data set. Curiously, the Netherlands and Germany (nl and de) seem to be especially partial to hierarchical directories.
Bright blue dots are rarer than red ones; it’s easier to build a site with 100,000 outbound links than it is to persuade 100,000 other sites to link to yours. The biggest blue dot is for wordpress.org, and I know the secret of that site’s popularity. If you have a self-hosted WordPress blog (like this one), the software comes with a built-in link back to home base.
Another conspicuous blue dot is gmpg.org, which mystified me when I first noticed that it ranks fourth among all sites in number of incoming links. Having poked around at the site, I can now explain. GMPG is the Global Multimedia Protocols Group, a name borrowed from the Neal Stephenson novel Snow Crash. In 2003, three friends created a real-world version of GMPG as a vehicle for the XHTML Friends Network, which was conceived as a nonproprietary social network. One of the founders was Matt Mullenweg, who was also the principal developer of WordPress. Hence every copy of WordPress includes a link to gmpg.org. (The link is in the <head> section of the HTML file, so you won’t see it on the screen.) At this point GMPG looks to be a moribund organization, but nonetheless more than a million web sites have links to it.
Networkadvertising.org is the web site of a trade group for online advertisers. Presumably, its 143,863 inbound links are embedded in ads, probably in connection with the association’s opt-out program for behavioral tracking. (To opt out, you have to accept a third-party cookie, which most people concerned about privacy would refuse to do.)
Still another blue-dot site, miibeian.gov.cn, gets its inward links in another way. If I understand correctly, all web sites hosted in China are required to register at miibeian.gov.cn, and they must place a link back to that site on the front page. (If this account is correct, the number of inbound links to miibeian.gov.cn tells us the number of authorized web sites in China. The number in the 2012 data is 289,605, which seems low.)
One final observation I find mildly surprising: Measured by connectivity, these 112 sites are the largest on the entire Web, and you might think they would be reasonably stable over time. But in the three years since the data were collected, 10 percent of the sites have disappeared altogether: Attempts to reach them either time out or return a connection error. At least a few more sites have radically changed their character. For example, serebella.com was a directory site that had almost 700,000 outbound links in 2012; it is now a domain name for sale. Among web sites, it seems, nobody is too big to fail.
The table below lays out the numbers for the 112 sites. It’s sortable: Click on any of the column headers to sort on that field; click again to reverse the ordering. If you’d like to play with the data yourself, download the JSON file.
| site | inlinks | outlinks | total links | % inbound |
|---|
I get 404s on these resources, which prevents the second diagram or the table from rendering:
http://bit-player.org/2015/extras/webgraph/d3/d3.min.js
http://bit-player.org/2015/extras/webgraph/packages.js
http://bit-player.org/2015/extras/webgraph/whales.js
http://bit-player.org/2015/extras/webgraph/sorttable.js
Interesting post, though - thanks!
Thanks for letting me know. WordPress was mucking about with relative URLs. Fixed now, I think.
I’ve been thinking about your “too big to fail”, and I have a theory. I suspect that sites with many incoming links are much more valuable, and are less likely to simply shut down. However, sites with many outgoing links and few incoming links aren’t necessarily “big” in any meaningful sense — now that I’ve read about the Common Crawl data, I could create such a site myself in a few hours.
So if you look at the 10% of the sites that don’t respond any more, what does their “% Inbound” look like?
Spot on! All but one of the defunct sites had very few inbound links; they were mainly web directories. The exception is posterous.com, a blog-hosting service that shut down in 2013. They had 53,000 inbound links.
Pleases take a look on scale-free networks and its vulnerability.
The topic has been extensively studied by physicists.
The power-law that you observe in the connectivity (links) per node (sites) shows that the web is scale-free which has some specific proprieties.
A high number of websites with hardly any inbound/outbound links does not surprise me, because many domains are only registered in order to sell them. Those “for sale” domains have hardly content and hence no or only a few links. Other domains are only registered to defend a trademark and do nothing or forward to the main domain of the company. Then there are single-serving sites which typically don’t have many links either.
The high number of such sites could be surprising, because we don’t encounter them very often. But that seems plausible actually. When browsing the web, you’d expect that we click more often on links to sites that have many inbound links, because, well, there are more links to them. And search engines use the number of inbound links as an important ranking factor, so we are much more likely to be sent to highly connected sites by search engines, too.
(Note: I’ve not verified these thaughts by looking at collected data. Other factors that I’ve not considered could be more important.)
The mystery, if there is one, is not so much why those isolated sites exist as how they got into the Common Crawl data set. A crawl starts with an initial set of seed URLs, then follows links found at those sites to explore the rest of the Web. Thus if a site has no inbound links, it can appear in the crawl results only if it is one of the seed URLs. Which leads to the further question: Why would 6.7 million of the seed URLs be sites that no one ever bothers to link to?
My best guess is that the answer lies in some form of web spam or search-rank manipulation. There’s an underworld of web sites that aren’t really meant for human consumption. There are link farms and content farms, and doubtless other schemes I could never dream up. Maybe the nature of the linkless sites will become clearer if I get around to actually looking at some of them.