Read the latest...

The Bits Come Out to Play Again
The bit-player website has been suffering from neglect and loneliness; it’s the Tamagotchi I failed to nurture. I write this post—my first in almost two years—to announce that bit-player is coming back from the not-quite-dead. I have rebuilt the infrastructure of the site, and new stories are on the way.
More to read...
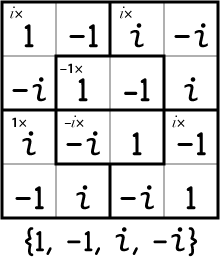
Kenken-Friendly Numbers
Kenken is the funny-page puzzle that allows the number nerds among us to strut their stuff. And it’s not limited to the integers 1 through 6 or the operations +, –, ×, ÷.

Foldable Words
In the spring of 1967 I had a girlfriend. After school we would meet at the Maple Diner. One afternoon I noticed she was fiddling intently with the wrapper from her straw, folding and refolding.
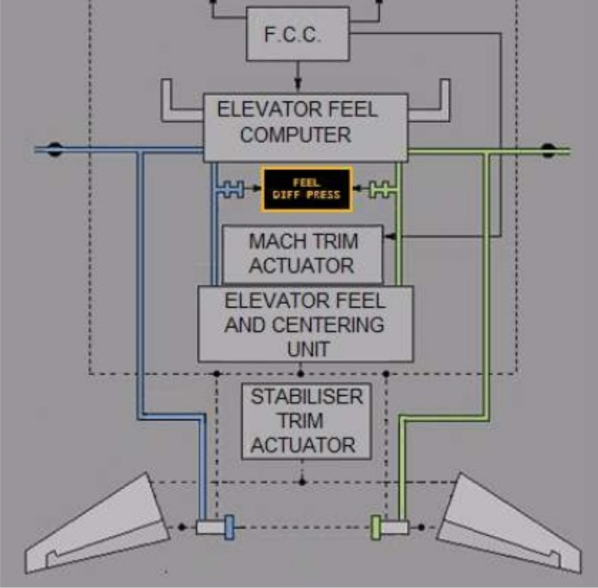
737: The MAX Mess
By all appearances, the rogue behavior of the 737 MAX control system was triggered by a malfunction in a single sensor. That’s not supposed to happen in aviation.
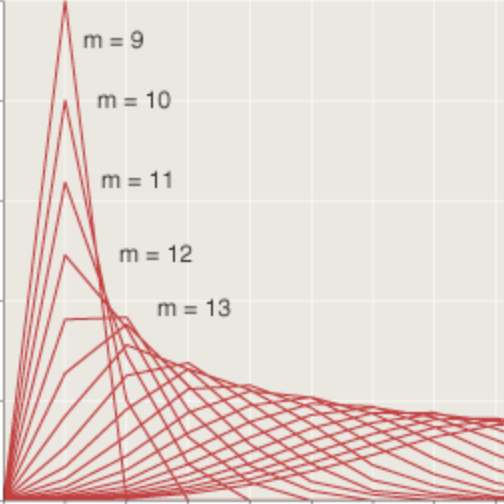
Counting Sums and Differences
On a research-level math problem that seems to involve nothing more exotic than counting, adding, and subtracting.
A Double Flip
How'd you like to be in charge of flipping mattresses in the Hilbert Hotel, which has infinitely many beds?
Sunshine In = Earthshine Out
Computer models of the Earth‘s climate have become forbiddingly complex, but even a simplistic program reveals interesting behavior.