Read the latest...
It Was Twenty Years Ago Today...
Marking two decades of playing with bits, and again musing about tools and technologies for communicating in words, pictures, equations, and code.
More to read...
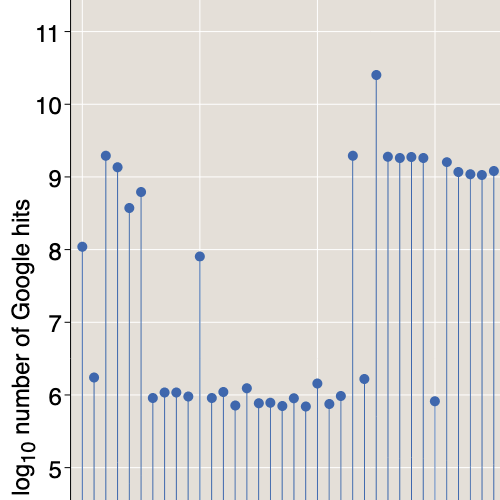
600613
Pick a number, N, then try searching for it on the web via Bing or Google (or maybe the leet version of Google).

The Ormat Game
Fun and games with permutation matrices. What a hoot!

Probabilities of Probabilities
Probabilities are a tool for coping with uncertainty. But what if the probabilities themselves are uncertain?

Rashid’s Bits
These 1s and 0s are woven into the upholstery fabric of the seats in an auditorium at Carnegie Mellon University. Does the pattern have any meaning?
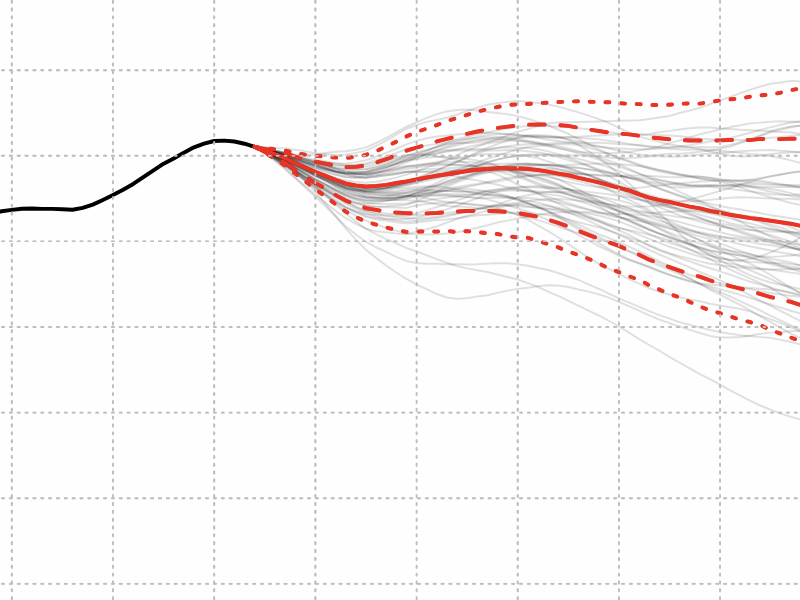
The Apex Generation
The number of children in the world has just passed its all-time peak, a prelude of global population decline.

Words for the Wordle-Weary
Can a computer program beat your score at Wordle? I don’t know, but it can beat mine.