Computing in the Classroom
by Brian Hayes
Published 8 April 2009
As the students file into the classroom, each of them reaches into a basket by the door and selects a ticket, on which a number is printed. For convenience, let’s assume the numbers are integers, they’re of reasonable size, and no two tickets bear the same number. Once everyone has settled down, the instructor assigns the class this exercise: Consult among yourselves and show me the ticket with the largest number.
How will the students solve this problem? Perhaps they pass all the tickets to one nimble kid in the first row, who thumbs through them looking for the maximum. This is a sequential algorithm, where the running time ought to be roughly proportional to N, the number of tickets. An obvious parallel solution is based on a tournament tree: Pairs of students compare their numbers, then the winners of each of these matches get together in pairs, and so on, until only one student remains. This routine yields an answer in about log2 N rounds of comparisons.
Here’s another idea. The students all stand up and shout out their numbers repeatedly, like commodity dealers in the trading pit. If a student hears a number larger than her own, she sits down and remains quiet thereafter. The last student standing has the largest number.
The efficiency of this shouting-match algorithm is hard to quantify. If we assume that everyone can yell and listen at the same time without confusion, then the problem of identifying the maximum number is solved instantaneously. For large N, however, that assumption is surely unrealistic.
A variant of the outcry algorithm is easier to analyze: A single student chosen at random calls out his number, and all those students with smaller numbers sit down. Then another student is selected from among those still standing, and the procedure is repeated until only one student remains. This algorithm also seems to have an expected running time of log2 N, since each round of eliminations should exclude (on average) half the students still in contention.
Suppose the students are asked to deliver the sum of the numbers, rather than the maximum. The tournament-tree computation adapts readily to this task, again requiring depth log2 N. On the other hand, I don’t know any reliable way to do addition by shouting.
What about calculating the average, or arithmetic mean, of the numbers? Of course this could be done by summing the numbers and then dividing by N—or by dividing first and then summing—but either of these strategies requires the students to count themselves before they can compute the average. Can’t they just use the tournament-tree algorithm to compute the average directly, as they did for the maximum and the sum? Suppose they replace the ‘max’ or ‘+’ operator with a new binary average operator, ‘•’, defined as (a • b) = (a + b)/2. Plugging this operator into the tree algorithm works just fine if N happens to be an exact power of 2, but otherwise it fails. In the case of N=5, for example, the computational tree might look like this:

The four values on the left are combined in a regular, symmetrical tree to yield the correct average, but then the fifth value has to be inserted in an extra, ad hoc operation. Applying the binary average operator at the top node of the tree would give a result of 3.75, whereas of course the true average is 3. The underlying problem here is that the averaging operator is not associative: (a • (b • c)) ≠ ((a • b) • c). [Forgive me if all this is thunderingly obvious to everyone but me. It actually took me a while to figure it out.]
One could fix this problem by passing pairs of numbers up the tree; one member of each pair is the running average, and the other member is a weight equal to the number of numbers that went into calculating that average. But this is just the sum-and-divide procedure in disguise. Let me note that there is a very simple algorithm for approximating the average. Have the students form random pairs repeatedly; in each pair, both students replace the value on their ticket with the average of the two values (in other words, they apply the ‘•’ operator). In this procedure the students never actually calculate either N or the sum, but both of those quantities are conserved as invariants of the computation. As the random process continues, all of the tickets eventually converge on the same value, namely the overall average. Experiments suggest that about log2 N rounds of random coupling yield a reasonably good approximation.
In judging the merits of these algorithms, my criteria have more to do with style than with computational complexity. My dislike for the sum-and-divide method probably has no firmer basis than stubborn prejudice. All the same, a computer in which the processors are people does seem to call for a particular style of program. Ideally (in my view) an algorithm for the classroom computer would be fully parallel (every student gets an equal chance to play), homogeneous (all the students get the same instructions) and local (students interact in small groups, without needing to know much about the global state of the system—such as the value of N). An algorithm gets extra points if it exploits the mobility and flexible communication patterns of human computers.
So here’s another challenge for the class. As before, the students take numbered tickets, but now the instructor asks to see the ticket with the median number—the value that is larger than half the other numbers and smaller than half. (Let’s make life easy and assume that N is odd.) Here is a median-finding algorithm—a variation on a method sometimes called Quickselect—that I would like to believe a group of students might invent. First, all the students raise their right hand. Then they repeat the following series of steps until the median is identified.
- Choose a student at random from among those who have a hand raised. This student’s ticket number is designated the pivot.
- All students whose number is smaller than the pivot line up on the left and those with larger numbers line up on the right.
- If the two lines are of equal length, then the pivot is the median. Stop.
- Otherwise, all students in the shorter line lower their hand (if it’s not down already); the pivot student also lowers her hand.
- Repeat.
The expected number of times the loop will be executed again appears to be approximately log2 N. Note that in this hand-waving algorithm the students never have to sort themselves. The method also requires no counting—not even for the comparison of line lengths. But we do assume that all the students can simultaneously compare their ticket numbers with the pivot.
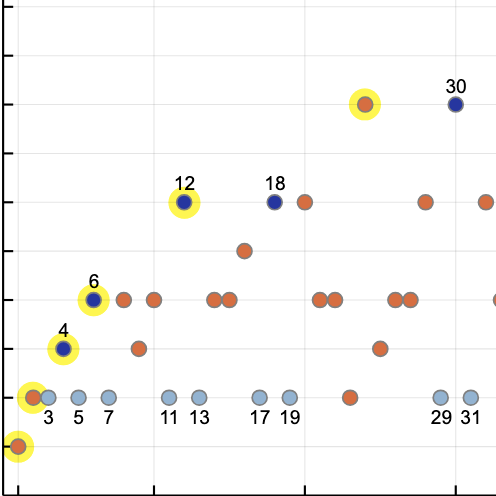
The diagram below shows an example calculation. The green dots at the top of each configuration are the successive pivots; students holding lesser and greater numbers are queued up to the left and right of the pivot; blue dots represent numbers still eligible for consideration as pivots (i.e., students with raised hands); red dots are numbers that have been excluded because at some stage of the computation they were in the shorter queue or were pivots that turned out not to be the median.

One could dream up plenty of other exercises to keep the students busy. They could search for subsets of numbers with special properties, such as Pythagorean triples. They could be asked to identify the longest sequence of consecutive integers in the set of numbers they hold. And then there’s the balanced subset-sum problem: The students divide themselves in two groups in such a way that the sums of the numbers in the groups are equal, or as close as possible to equal. (This is an NP-complete problem, but many instances yield easily to the right heuristics.)
The various marching-band patterns and parliamentary shouting matches described above are my own fantasies about how groups of people might “enact” algorithms. I’m curious to know how real students, in a real classroom setting, would actually go about solving such problems. Would they adopt the kinds of local and homogeneous algorithms I find aesthetically pleasing? Or would they favor a simpler and more pragmatic approach? In some cases I suspect that the ruse of passing all the tickets to the class whiz might well be fastest and most reliable way to get an answer. Moreover, for any other approach the time needed for the students to choose an algorithm and organize themselves may well exceed the execution time. Indeed, the very process of coming to agreement on how to solve a problem calls for significant group dynamics; this is not something we see in other kinds of parallel computers.
Another interesting point about people as processors is that their capabilities are not very sharply defined. For example, most algorithms assume that comparisons are strictly pairwise; a predicate such as ‘>’ or ‘=’ is applied to exactly two numbers, and the efficiency of the algorithm is measured by counting those operations. But it seems likely that three or four students could huddle together and find the maximum of their numbers about as quickly as two students could. Thus the complexity of some algorithms might be reduced to log3 N or log4 N.
On the other hand, I’ve assumed the existence of some primitive operations that may be difficult to realize. In particular, the axiom of random choice seems a little dubious in this context. If a group of students is asked to choose one their members at random, how do they go about it? Can they always do it in unit time?
There’s also the question of how such algorithms scale as N increases. A scheme that works well in a classroom with 30 students might not be ideal in a lecture hall with 300. And surely the process would go very differently in a stadium holding 30,000.
I assume that many experiments of this kind have been tried over the years, although I haven’t found much literature on the subject. (Perhaps the closest match is a 1994 article by Bachelis, James, Maxim and Stout; they also note the scarcity of published material.) If anyone has reports from the field, I’d be delighted to learn about them.
Update 2009-04-14: Thanks to the commenters for some particularly helpful and lucid responses. I would like to explore one of these themes a little further.
Mario Klingemann’s “small optimization” to the outcry algorithm is more than just a minor improvement; it corrects an outright bug in the procedure I described. Klingemann notes that when a student calls out a number and all the students with smaller numbers sit down, the calling student must also sit unless no one else remains standing. This is important! Consider the difference it makes when N=2.
So which version of the algorithm—my buggy one or Klingemann’s correct one—matches up with JeffE’s analytic result showing that the expected number of rounds is the Nth harmonic number? In the graph below the harmonic numbers H(N) are represented by the red line; the green and blue lines are empirical results averaged over 100,000 repetitions of programs implementing the two algorithms.

For a given N, the Klingemann result is H(N) – 1/2; the buggy algorithm yields H(N) + 1 (asymptotically, for large N).
Responses from readers:
Please note: The bit-player website is no longer equipped to accept and publish comments from readers, but the author is still eager to hear from you. Send comments, criticism, compliments, or corrections to brian@bit-player.org.
Publication history
First publication: 8 April 2009
Converted to Eleventy framework: 22 April 2025
In response to the paragraph:
“A variant of the outcry algorithm is easier to analyze: A single student chosen at random calls out his number, and all those students with smaller numbers sit down. Then another student is selected from among those still standing, and the procedure is repeated until only one student remains. This algorithm also seems to have an expected running time of log2 N, since each round of eliminations should exclude (on average) half the students still in contention.”
It is true that this algorithm has expected time O(\lg N), but showing this formally is not as easy as one would want. This is really a probabilistic recurrence relation that, unlike normal recurrence relations, require clever tricks to solve. This particular recurrence can be solved using techniques from section 1.4 of “Randomized Algorithms”, by Motwani and Raghavan.
Actually, Michael, the analysis of that algorithm is easy if you look at it the right way. The expected number of rounds is precisely the Nth harmonic number 1 + 1/2 + 1/3 + … + 1/N, which is between ln N and ln N + 1.
The key insight is that the student with the kth smallest number shouts with probability 1/k. Ignore all but the top k students. One of the top k students, chosen uniformly at random, shouts first.
There are a couple of papers that might interest you depending on, well, your interests. They deal with the following:
- suppose we already have a small-space sequential algorithm (e.g. for sum, the students assign a leader, who reads the numbers one by one and just remembers the sum so far)
- then can we necessarily get a distributed algorithm that works for an arbitrary computation tree?
http://arxiv.org/abs/cs.CC/0611108
http://arxiv.org/abs/0708.0580
The second one is by me :) coming as a byproduct of my master’s thesis. In general I found this to be a natural and interesting area whose theory is somewhat underdeveloped.
JeffE:
Ah, your solution is indeed much easier. Thanks!
I like your stadium idea. Here’s a puzzle. As people enter a stadium for a sporting event (Bit Players vs. Bit Twiddlers), they are each given a ticket with a number (positive integer) on it. At halftime, you are to compute the mean, mode, and median. You can use the Jumbotron. Assume the spectators will cooperate with reasonable requests - maybe prizes will be handed out?
A small optimization to the outcry method: the student that has shouted his number can also sit down if there is anybody else but him still standing after his shout, since all the other must have numbers higher than his.
Just to be clear, although the outcry algorithm “seems to have an expected running time of log2 N, since each round of eliminations should exclude (on average) half the students still in contention,” the analysis shows that, at approximately ln(N), the run time is in fact about 30% faster than that.
So, Barry, just to be clear: What you’re suggesting is that the blue curve in the graph above is not y = H(N) – 1/2 but rather y = H(N) – γ (where γ is the Euler-Mascheroni constant, approximately 0.577). (H(N) is asymptotically ln(N) + γ.)
I don’t think so. Here are the successive differences between the red and blue curves, for N=2 through N=2048:
0.5, 0.5001935, 0.49465728, 0.49561906, 0.50111556, 0.5011015, 0.49634743, 0.49349594, 0.5049672, 0.5029931, 0.49814177
Brian, no, all I meant to point out is that ln(N) =ln(2)*log_2(N).
Sorry for the confusion, Barry. I guess two messages that both include the phrase “just to be clear” are almost certain to be muddled.
I do understand your observation that the number of rounds needed to find the maximum looks *approximately* like ln(N). But I believe that’s a coincidence, that the correct expression is H(N) - 1/2. This is close to ln(N) simply because 1/2 is close to γ.
Just to be clear, the reasoning goes as follows. JeffE, in the second comment above, explains where H(N) comes from. The -1/2 term comes from Mario Klingemann’s optimization: When only two students are left standing, it doesn’t take H(2)=1.5 rounds to identify the larger number. Instead, the N=2 game is over in a single round, no matter what the initial random choice. In my buggy version, the N=2 case takes 1 + 1/2 + 1/4 + … = 2 rounds.
Brian, I clearly didn’t make my point as clearly as I thought! I wasn’t concerned with the small difference between H(N) and ln(N), or with the small difference between your buggy algorithm and Klingemann’s optimization. I just wanted to point out something I think got overlooked: There is a *big* difference between what you expected the expected running time to be for an outcry algorithm and what the run time actually is.
In the original post, you gave a perfectly sensible, intuitive explanation why the expected run time should be lg(N) (using “lg” for “log base 2″), namely that each step cuts things in half on average. But in fact the expected run time is closer to ln(N), which is smaller by a *multiplicative* factor of ln(2) = 0.69. In other words, the outcry algorithm, whether buggy or not, runs about 30% faster than the parallel “tournament tree” algorithm described in the second paragraph of the post.
So I meant to raise an implicit question: What’s wrong with your perfectly sensible, intuitive explanation for a lg(N) run time?
Barry:
It’s not enough that I make all the mistakes around here? I have to diagnose and explicate them as well?
I’m working on it. But I’m busy. I still have a day job. I could use a little help. So let me throw the question back at you.
Suppose I ask you to choose n numbers uniformly at random from the interval [0,1) and calculate their product. You reason that the numbers will have an average value of 1/2, and so the expectation value of the product is 1/2^n.
Now I suggest a slightly different procedure. Again you select a number uniformly at random from the interval [0,1). The selected number — call it p — partitions the interval into two subintervals, [0,p) and [p,1). Choose one of these subintervals at random and select a new p from this range. Repeat n times and calculate the product of the successive p‘s. Again each interval is “on average” bisected, but the expected value of the product is not 1/2^n? What is it?
See also the broken-stick problem.
Well the spam screening confused me for a little while…lol
Excellent your solutions seems to be a lot better and easier to understand.